Okera Version 2.6 Release Notes¶
This topic provides Release Notes for all 2.6 versions of Okera.
2.6.8 (1/10/2022)¶
an additional upgrade of log4j to resolve additional instances of the Log4Shell vulnerability.
Bug Fixes and Improvements¶
- Arrays with duplicate names are now unnested successfully.
2.6.7 (12/20/2021)¶
Bug Fixes and Improvements¶
- This release contains an additional upgrade of
log4jto resolve additional instances of theLog4Shellvulnerability.
Notable and Incompatible changes¶
- In past versions, Okera's operational logs did not use a partitioning scheme when uploading. This made it hard to locate the logs you needed and, in some environments, increased the time to list the log files. With this release, a new configuration option,
WATCHER_LOG_PARTITIONED_UPLOADShas been added to the configuration file to enable partitioned log uploads. Valid values aretrueandfalse. When enabled (true), operational log files will use theymd=YMD/h=H/component=Cpartitioning scheme for operational log file uploads. By default, this setting is disabled (false) so older clusters are not affected. However, in a future version of Okera, it will be enabled by default, so Okera recommends that users adopt this in new deployments.
2.6.6 (12/13/2021)¶
This release contains an upgrade of log4j to resolve the Log4Shell vulnerability.
Bug Fixes and Improvements¶
- Fixed an issue that occurred while listing databases when Okera is connected to an external Hive metastore (HMS).
- Fixed an issue in which crawlers for the Hadoop File System (HDFS) were not working.
2.6.5 (10/22/2021)¶
Bug Fixes and Improvements¶
-
Resolved a crash that occurred when scanning ORC data.
-
Corrected the date offset conversion used for dates before UNIX epoch time. This previously could be off by one for certain time zones.
-
This release resolves some incorrect processing of the
Create Temporary Table/Viewstatement by a Spark client library. The fix specifically handles cases when theRecordServiceTableis specified with a direct table name and aLASTclause or when theRecordServiceTableis specified using aSELECTstatement. -
Added a guard that rejects queries larger than a specified byte size. Use the MAX_REQUEST_SIZE_BYTES environment variable to configure the byte size limit. The default size is 52751601 bytes, which is approximately 52MB. Queries that are smaller than this are not guaranteed to succeed and may fail if they encounter other guards.
-
Added support that scans Avro data files with
enumdata types containing default values. In previous versions, onlyenumdata types with no default values were supported. -
The Java client libraries can now fail due to misconfiguration-related authentication errors. These errors have been and continue to be rejected on the server but adding them to client checks improves error diagnosis. This feature is optional but is enabled by default for Databricks. To enable it, set the REQUIRE_AUTHENTICATED_CONNECTIONS environment variable to
true.
2.6.4 (09/10/2021)¶
Bug Fixes and Improvements¶
- Fixed several issues when scanning nested types that could cause a crash or query failure.
- Fixed an issue when using
Symlinktables where the manifest file containeds3a://...URIs instead ofs3://...URIs. - Fixed an issue where new partitions were not being discovered for the audit log tables when automatic partition recovery was disabled.
- Fixed an issue when creating non-Delta Parquet tables in Databricks when connected to Okera.
- Improved support for creating views in Databricks that contain SQL that cannot be analyzed by Okera.
- Improved the performance of authorizing very wide tables with many tags on them.
- Fixed an issue when trying to create tables in Databricks using non-AWS-S3 paths (e.g.,
abfs://,gs://, etc.). - Fixed an issue when generating a JWT that would use the server's time zone instead of UTC to calculate the expiry date.
Notable and Incompatible Changes¶
- When privacy functions such as
mask()andtokenize()apply to a column that is a complex type (e.g.,STRUCT) in Databricks, it will now convert those columns tonullas the new default behavior. To revert to the previous behavior, set theCOMPLEX_TYPES_NULL_ALL_TRANSFORMSconfiguration tofalse.
2.6.3 (08/22/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue where some permissions appeared twice on the Permissions tab in the Datasets page.
- Fixed an issue when creating a table using the Spark CSV provider in Databricks.
- Fixed an issue when querying struct types using the new native Databricks integration.
- Fixed an issue when autotagging tables that had
STRUCTvalues. - Fixed an issue that could cause a crash in the Enforcement Fleet workers when scanning an unnested table.
2.6.2 (08/02/2021)¶
Bug Fixes and General Improvements¶
- Fixed an issue that could prevent startup if a bad regular expression was configured for an autotagging rule.
- Fixed an issue when creating a crawler and using the "Dataset files are not in separate directories" option.
- Fixed an issue when cascading tags on nested parts of complex columns to child views when multiple tags are present.
- Fixed an issue that can occur with MySQL 5.7 as the backing database.
- Added the ability to configure the timeout for Presidio autotagging using the
OKERA_PRESIDIO_TIMEOUT_MSconfiguration parameter. - Okera's Java client libraries will now detect when running in a Domino Data Labs environment and automatically leverage the auto-generated JWT specified in
DOMINO_TOKEN_FILE. - Improved the behavior of non-alpha characters when using
tokenize()in a Databricks environment. - Added the ability to blacklist specific tags from Presidio autotagging matches using
OKERA_PRESIDIO_TAG_BLACKLIST, e.g.,OKERA_PRESIDIO_TAG_BLACKLIST: pii.address. - Added the ability to specify that Okera is connecting to a pre-existing HMS/Sentry to avoid any changes to those schemas - enable this by setting the
CATALOG_EXISTING_HMS_SCHEMA: trueconfiguration parameter. - Fixed an issue when loading tables that have type definitions that contain Okera keywords (this typically only happens with a pre-existing HMS).
- Fixed an issue when authorizing view access for Databricks when all views are external.
- Fixed an issue when using the legacy and deprecated input format
com.uber.hoodie.hadoop.HoodieInputFormatfor Hudi - please switch to usingorg.apache.hudi.hadoop.HoodieParquetInputFormat. -
Improved SSL handling for Okera's Policy Engine (planner) and Enforcement Fleet worker. You can enable this by setting:
RS_SSL_ENABLED: trueRS_ARGS: --ssl_enable=true --ssl_private_key=/path/in/pod/to/key --ssl_server_certificate=/path/in/pod/to/cert
See RS_ARGS Options.
-
Added configuration options for clients to connect to the Policy Engine (planner) and Enforcement Fleet worker using SSL:
- For Hive/Spark:
recordservice.planner.connection.ssl,recordservice.worker.connection.ssl - For Presto:
okera.planner.connection.ssl,okera.worker.connection.ssl - Alternatively, setting the
RS_SSL_ENABLEDvariable will auto-set these.
- For Hive/Spark:
- Added the ability for nScale Enforcement Fleet workers to also have SSL enabled - in addition to the above parameters, you also need to enable authentication on the client using
recordservice.worker.force-auth(for Hive/Spark) andokera.worker.force-auth(for Presto). - Fixed an issue when dropping partitions in Databricks.
- Fixed an issue where server errors would cause an empty database list to be displayed in the Okera UI - the error will now be properly reported.
- Improved performance of listing datasets in the Okera UI.
- Added support for using
NULL DEFINED ASwhen creating a table. - Added the ability to disable autotagging of complex types by setting the
ENABLE_COMPLEX_TYPE_AUTOTAGGINGconfiguration value tofalse.
Notable and Incompatible Changes¶
- This release contains an upgrade of the Alpine base image from 3.13 to 3.14, which upgrades the embedded Python from 3.8.x to 3.9.x (to address a Python CVE).
2.6.1 (05/25/2021)¶
Bug Fixes and General Improvements¶
- Fixed an issue where the Okera UI would fail to render using Safari.
- Fixed an issue where previewing data in the Registration page could fail.
- Fixed an issue where paginating to past the first page of crawled tables in the Registration page could fail.
2.6.0 (05/13/2021)¶
New Features¶
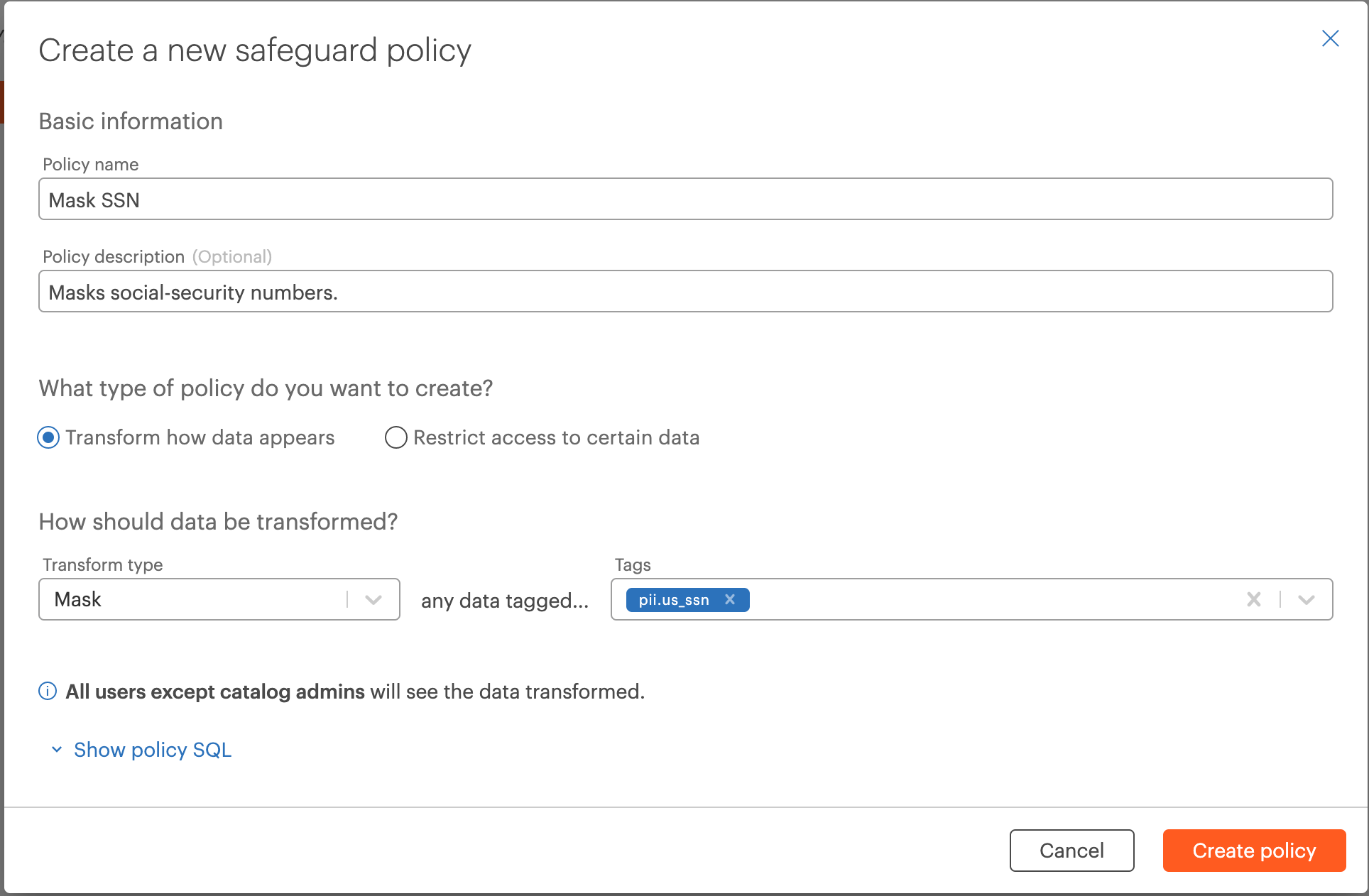
Safeguard Policies for Catalog-Wide Compliance (Beta)¶
You can now set up catalog-wide 'Safeguard' policies to ensure certain specified data is always masked, or restricted to certain users, regardless of lower-level permissions granting access to it. For example, you could set up a Safeguard policy to mask data tagged social-security number across the entire catalog. Read more here.
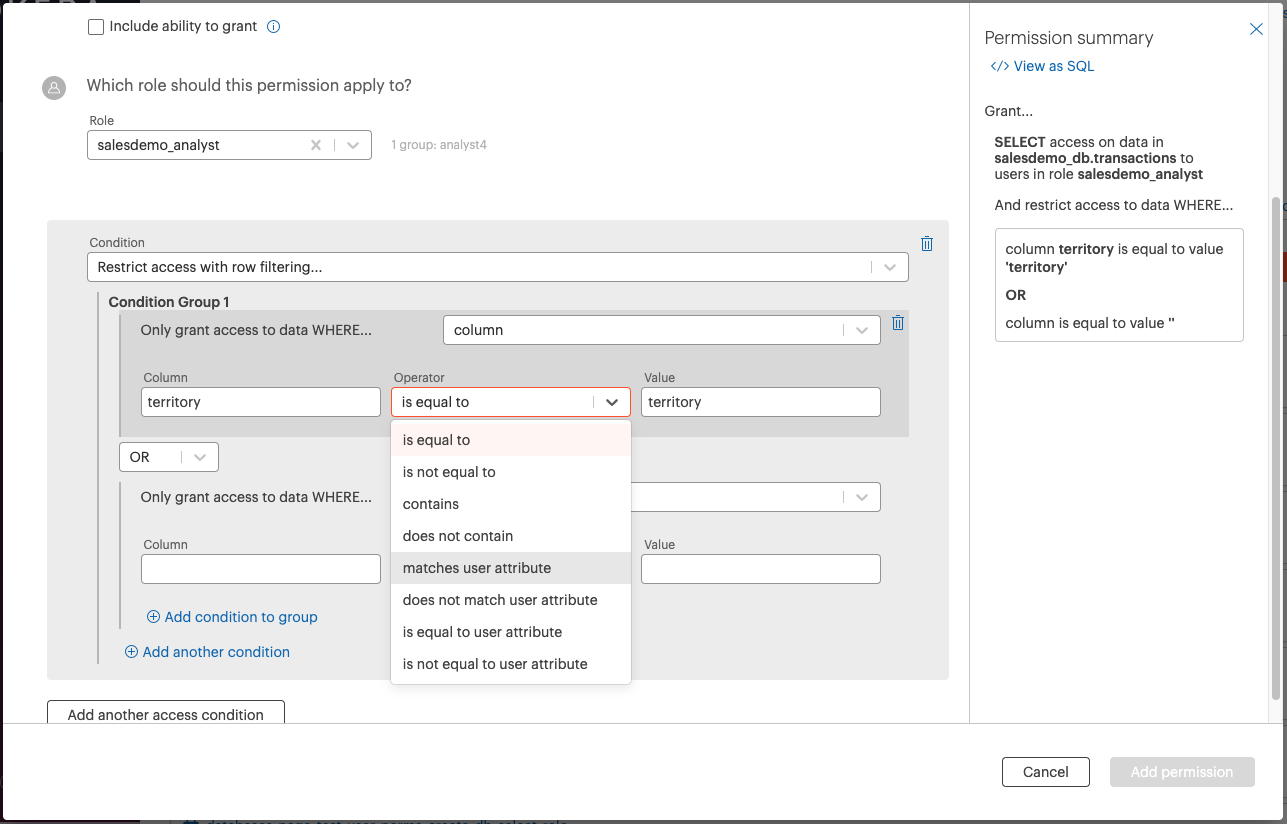
Row-Level Security Expression Builder and User Attribute Policy Building Improvements¶
New UI experience to easily create granular row filtering permissions, which leverage user attributes. Users will have the option to create column and user attribute-based access conditions or can customize their experience by using the custom SQL expression option.
Data stewards and admins who create these policies will now be able to manage these policies in the permissions list or directly on the specific role in the roles page.
You can read more about user attributes here and how to implement user attribute-based policies here.
Easily Connect and Protect BigQuery Data¶
You can now create a Google BigQuery connection in Okera and create a crawler to register tables from BigQuery inside the Okera catalog. Read more here.
Additional Support for Azure and Google Cloud¶
Azure KeyVault Support¶
Okera now supports using Azure KeyVault as a source for secrets, which can be leveraged when creating connections to other data sources such as Azure Synapse, Azure SQL, Snowflake, and others. You can read more about passing sensitive credentials here.
Google Cloud Secret Manager¶
Okera now supports using Google Cloud Secret Manager as a source for secrets, which can be leveraged when creating connections to other data sources such as Azure Synapse, Azure SQL, Snowflake, and others. You can read more about passing sensitive credentials here.
Audit Logs in Google Cloud Storage¶
You can now configure Okera to store the audit logs in Google Cloud Storage. You can read more about this here.
Additional Support for PrestoSQL¶
Client Library Support for PrestoSQL 350¶
Okera has added support for PrestoSQL version 350 in the PrestoSQL client library support.
Using PrestoSQL as the Okera Presto Engine (Beta)¶
Starting in 2.6.0, it is possible to utilize PrestoSQL as the Presto engine that Okera uses, instead of PrestoDB.
To do this, you can either specify it with okctl during upgrade (you can use either prestodb or prestosql as the values):
okctl upgrade latest --presto-engine=prestosql
or you can use the quay.io/okera/prestosql:2.6.0 image in your Kubernetes manifests.
Note: PrestoSQL has its own JDBC driver that you can download from
s3://okera-internal-release/2.6.0/prestosql-jdbc-driver/presto-jdbc-350.jar. In a future Okera release, PrestoSQL (and eventually the Trino-based releases) will become the default engine (with an option to switch back to PrestoDB), as it provides improved performance and capability.
Added Support for Databricks 7.5+¶
Okera now supports Databricks 7.5 and 7.6.
Bug Fixes and General Improvements¶
- Several improvements to for Delta tables that were created by Databricks with limited metadata.
- Fixed an issue in the Databricks client integration when loading tables that only had metadata in the Spark properties.
- Fixed an issue in the Databricks client integration for partitioned tables.
- Added support for discovering ORC-based datasets using Data Registration crawlers.
- Fixed an issue when rewriting queries for Databricks.
- Add pushdown support for the
sets_intersectbuilt-in string function (not applicable for Dremio). - Fixed an issue when dropping a partitioned table using mixed-case.
- Added the ability to set the user attribute cache invalidation interval by setting the
OKERA_USER_ATTRIBUTES_CACHE_THRESHOLD_MSconfiguration setting (default is 5 minutes). - Added the ability to invalidate the connection pools for JDBC-backed tables using the
INVALIDATE CACHED DATACONNECTIONDDL (only available for system administrators). - Fixed an issue when using multiple Snowflake warehouses in the same Snowflake account in the same Okera deployment.
- Added datatype-variants for
mask()for non-text types (the masked value will be the zero value for that type). - Improved the Okera UI cookie security by restricting to the cluster's domain name.
- Fixed an issue when an error occurs during login - the error will now be displayed instead of an infinite redirect loop.
- Fixed a bug where Okera was not properly escaping column names in the Policy Builder UI.
- Improved performance on wide tables with many tags.
- Improved Policy Builder experience.
- Improved the experience of editing attributes on columns on the Data page.
- Policy Builder now shows the number of groups associated with selected role when granting from the data page.
- The Group filter on the Users page is now multi-select.
- Updated style and usability for how permissions are displayed on the Data pages.
- Improved copy behavior on table rows - copying a row will now copy CSV instead of JSON.
Notable and Incompatible Changes¶
- Users with VIEW_AUDIT on any database or dataset will now automatically have access to the Reports page in the UI.
They will also need access to the
okera_system.reporting_audit_logsview to query the audit logs and load the page correctly. - Removed the deprecated Datasets page. This page was deprecated and disabled by default in 2.3.
Login Cookie and Authentication Changes¶
- Downgrading from 2.6.0 to 2.5.0, or to any prior version of Okera other than 2.5.1, in the same cluster will cause a UI login failure since the cookies are not compatible.
- If a cluster uses
SSL_FQDN, access the UI via IP address will no longer work due to recent cookie security fixes. - The
api/get-tokenendpoint now returns401if not provided a token instead of403.