Okera Version 2.7 Release Notes¶
This topic provides Release Notes for all 2.7 versions of Okera.
2.7.9 (3/23/2022)¶
Bug Fixes and Improvements¶
- Fixed a bug in which the date offset in Snowflake did not account for daylight savings time.
-
Added configuration settings
PRESTO_HTTP_CLIENT_MAX_CONNECTIONS_PER_SERVERandPRESTO_HTTP_CLIENT_MAX_REQUESTS_QUEUED_PER_SERVER. These settings customize the Presto configuration properties that control the maximum number of concurrent connections for a server(http-client.max-connections-per-server) and the maximum number of requests queued per destination (http-client.max-requests-queued-per-destination). See Configuration. If these values are not specified in Okera, the values specified in your Presto environment are used (20 forhttp-client.max-connections-per-serverand 1024 forhttp-client.max-requests-queued-per-destination). -
Fixed a race condition that occurred when invoking Hive UDFs.
- The default internal RPC timeouts used by the Okera client and server have been increased. After SASL authentication, the RPC timeout has been increased from 600000 ms (10 minutes) to 3,600,000 ms (60 minutes). The server RPC timeout has been increased from 120000 ms (2 minutes) to 1,800,000 ms (30 minutes).
- Fixed an issue in which an evicted worker pod caused node membership registration to fail.
- Fixed an issue that could cause excessive memory usage when reading many small Avro files.
2.7.8 (1/10/2022)¶
This release contains an additional upgrade of log4j to resolve additional instances of the Log4Shell vulnerability.
Bug Fixes and Improvements¶
- Arrays with duplicate names are now unnested successfully.
2.7.7 (12/20/2021)¶
Bug Fixes and Enhancements¶
- This release contains an additional upgrade of
log4jto resolve additional instances of theLog4Shellvulnerability.
Notable and Incompatible changes¶
- In past versions, Okera's operational logs did not use a partitioning scheme when uploading. This made it hard to locate the logs you needed and, in some environments, increased the time to list the log files. With this release, a new configuration option,
WATCHER_LOG_PARTITIONED_UPLOADShas been added to the configuration file to enable partitioned log uploads. Valid values aretrueandfalse. When enabled (true), operational log files will use theymd=YMD/h=H/component=Cpartitioning scheme for operational log file uploads. By default, this setting is disabled (false) so older clusters are not affected. However, in a future version of Okera, it will be enabled by default, so Okera recommends that users adopt this in new deployments.
2.7.6 (12/13/2021)¶
This release contains an upgrade of log4j to resolve the Log4Shell vulnerability.
2.7.5 (11/18/2021)¶
Bug Fixes and Improvements¶
- Made corrections to Parquet file optimization.
2.7.4 (11/01/2021)¶
Bug Fixes and Improvements¶
- Added support that scans Avro data files with
enumdata types containing default values. In previous versions, onlyenumdata types with no default values were supported.
- This release makes Parquet file scan speed improvements work for files with statistics stored in deprecated fields.
2.7.3 (10/19/2021)¶
Bug Fixes and Improvements¶
- Resolved a crash that occurred when scanning ORC data.
-
This release improves Parquet file scan speeds for queries by evaluating filters against file statistics. Currently, this only supports filters on integer-type columns.
-
Query rewrites for Snowflake now support using array functions in Okera policies.
-
This release resolves some incorrect processing of the
Create Temporary Table/Viewstatement by a Spark client library. The fix specifically handles cases when theRecordServiceTableis specified with a direct table name and aLASTclause or when theRecordServiceTableis specified using aSELECTstatement. -
A
CREATE_TIMEcolumn was added to theall_tablessystem view. -
Corrected the date offset conversion used for dates before UNIX epoch time. This previously could be off by one for certain time zones.
-
With this release, Databricks connections via JDBC endpoint connect users correctly.
-
The Java client libraries can now fail due to misconfiguration-related authentication errors. These errors have been and continue to be rejected on the server but adding them to client checks improves error diagnosis. This feature is optional but is enabled by default for Databricks. To enable it, set the REQUIRE_AUTHENTICATED_CONNECTIONS environment variable to
true.
2.7.2 (09/28/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue that occurred while listing databases when Okera is connected to an external Hive metastore (HMS).
- Fixed an issue in which crawlers for the Hadoop File System (HDFS) were not working.
- Added a guard that rejects queries larger than a specified byte size. Use the MAX_REQUEST_SIZE_BYTES environment variable to configure the byte size limit. The default size is 52751601 bytes, which is approximately 52MB. Queries that are smaller than this are not guaranteed to succeed and may fail if they encounter other guards.
- Added options that will log the current application stack should a crash occur.
- Fixed a crash that occurred when reading Apache Avro data.
2.7.1 (09/09/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue when creating non-Delta Parquet tables in Databricks when connected to Okera.
- Improved the performance of authorizing very wide tables with many tags on them.
- Fixed an issue when using
Symlinktables where the manifest file containeds3a://...URIs instead ofs3://...URIs. - Fixed an issue where new partitions were not being discovered for the audit log tables when automatic partition recovery was disabled.
- Fixed an issue when trying to create tables in Databricks using non-AWS-S3 paths (e.g.,
abfs://,gs://, etc.). - Fixed an issue when generating a JWT that would use the server's time zone instead of UTC to calculate the expiry date.
- Improved support for creating views in Databricks that contain SQL that cannot be analyzed by Okera.
- Fixed an issue when autotagging tables that had
STRUCTvalues.
Notable and Incompatible Changes¶
- When privacy functions such as
mask()andtokenize()apply to a column that is a complex type (e.g.,STRUCT) in Databricks, it will now convert those columns tonullas the new default behavior. To revert to the previous behavior, set theCOMPLEX_TYPES_NULL_ALL_TRANSFORMSconfiguration tofalse. - Okera will now leverage Strict Transport Security (HSTS) when requesting pages over HTTPS, letting the browser know to never request those over HTTP for all subdomains. If users were accessing web pages in subdomains of the Okera domain via HTTP where Okera's domain was hosted over HTTPS, this is no longer possible. Instead, host all subdomains over HTTPS.
- The Okera REST API (
cdas-rest-serverservice) now explicitly setsCache-Control: no-storeheaders for all mutable API resources. This ensures better security semantics when using a browser to access Okera resources.
2.7.0 (08/20/2021)¶
New Features and Enhancements¶
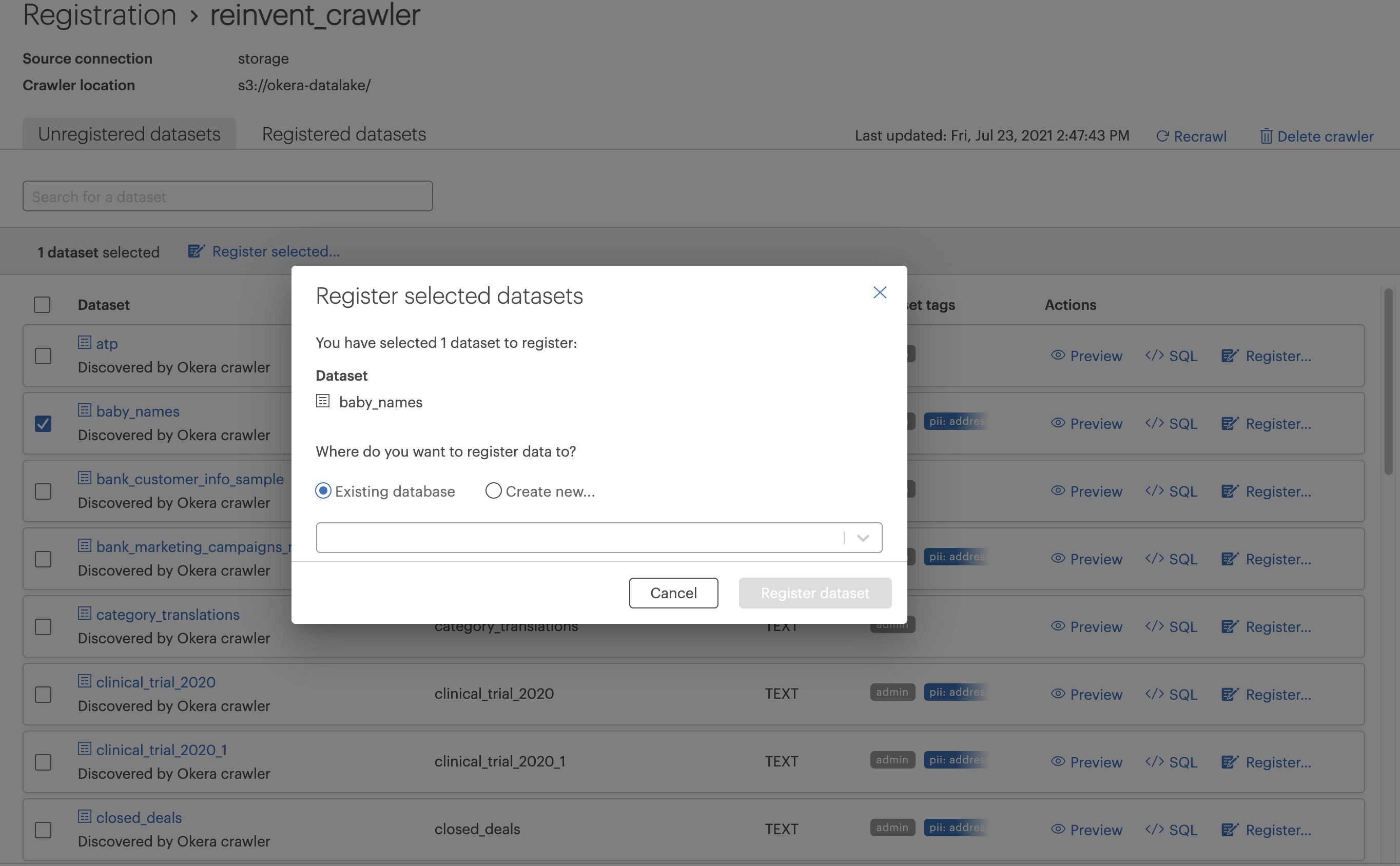
Registration Improvements¶
Okera's Data Registration UI has been significantly improved, now matching the look and feel of the rest of the Okera UI, as well as adding new functionality:
- Enhanced attribute editing, easing the review and modification of attribute assignments.
- Edit more table metadata, including table-level attributes, the table name and table- and column-level comments.
Reading Data Via Assume Role¶
When reading data from Amazon S3, Okera now supports the ability to assume secondary roles to read data, with different roles for different buckets.
For example, you can configure Okera to use role-a when reading data from s3://bucket-a and role-b when reading data from s3://bucket-b.
To configure this capability, use the BUCKET_TO_ROLE_MAP_FILE configuration setting, with the value being a path to a file (e.g., s3://path/to/mapping.json or file:///path/to/mapping.json) that has the following structure:
{
"version": "v1",
"buckets": {
"bucket-a": {
"role": "arn:aws:iam::<account>:role/role-a"
},
"bucket-b": {
"role": "arn:aws:iam::<account>:role/role-b"
}
}
Audit and Operational Log Storage¶
Okera now supports storing audit and operational log storage on ADLS Gen2 and Google Cloud Storage.
For ADLS Gen2, configure the WATCHER_AUDIT_LOG_DST_DIR and WATCHER_LOG_DST_DIR settings to a path such as abfs://okera@mycompany.dfs.core.windows.net/logs/audit/.
Note: Okera supports Azure Blob Filesystem Storage (abfs)
dfsURIs (*.dfs.core.windows.net), but does not supportblobURIs (*.blob.core.windows.net).
For Google Cloud Storage, configure the WATCHER_AUDIT_LOG_DST_DIR and WATCHER_LOG_DST_DIR settings to a path such as gs://mycompany/okera/logs/audit/.
DDL Improvements¶
-
Okera now supports adding table-level attributes when creating a table or views using
CREATE TABLEandCREATE VIEW. For example:CREATE TABLE users ( id BIGINT, name STRING ) ATTRIBUTE classification.sensitive -
Okera now supports adding multiple partitions in a single SQL command. For example:
ALTER TABLE rs.multi_add_partition_test_table ADD PARTITION(year='2020') LOCATION 's3://cerebrodata-test-readonly/readonlypartitiontest/year=2020/' PARTITION(year='2021') LOCATION 's3://cerebrodata-test-readonly/readonlypartitiontest/year=2021/' PARTITION(year='2022') LOCATION 's3://cerebrodata-test-readonly/readonlypartitiontest/year=2022/'
Databricks 8 Support¶
Okera now supports Databricks 8.0, 8.1 and 8.2 runtimes for the new native integration.
UI Improvements¶
- Okera now supports enabling all supported authentication types (AD/LDAP, OAuth, SAML and Token-based) enabled at the same time, including on the UI login page.
- It is now possible to filter the list of Connections by both the name of the connection as well as the underlying type (e.g., Snowflake, AWS Redshift, etc.).
- Okera's Policy Builder now allows editing policies that have granular row filtering permissions while retaining the structured builder UI.
- The Okera Presto JDBC driver is available to download on the System page.
Bug Fixes and General Improvements¶
- Fixed an issue where errors in the permissions table on the Data page were not shown properly.
- Fixed an issue where in the permission table on the Data page, permissions with grant option would not be shown correctly.
- Fixed an issue where extra whitespace could cause incorrect token parsing in
Authorizationheaders. - Fixed an issue where the directory settings in the Data Registration UI were not being applied.
- Fixed an issue with OAuth logins, where if originating from a deep link, the OAuth login would fail with an error due to an unrecognized redirect URL.
- Fixed an issue where conflict computation for new permissions included global policies.
- Fixed an issue where while creating or editing a permission in Policy Builder, access level dropdown could have options that were not actually available.
- Fixed an issue where the crawler could create a table with an invalid column name, rendering that crawler unusable by the system.
- Added the ability to control the Tags dropdown when editing a schema using the keyboard.
- Fixed an issue when renaming tables using
ALTER TABLE <table> RENAME TO <new table>. - Fixed an issue when creating a table using the Spark CSV provider in Databricks.
- Fixed an issue when querying struct types using the new native Databricks integration.
- Fixed an issue when running
SHOW CREATE TABLE <table>on a JDBC-backed table. - Fixed an issue that caused the same user to be displayed (with different casing) on the Users page.
- Fixed an issue when accessing a table in a database in cases where a table existed in the
defaultdatabase that had the same name as the original database.
Notable and Incompatible Changes¶
- The REST server endpoint no longer hosts the
/__statusendpoint. Wherehttps://mycompany.okera.com:8083/__statusused to returnokit will now return a404. If a status endpoint is needed, use/api/healthinstead: a200response indicates a functioning status. - The Data Registration UI does not support renaming tables when using AWS Glue as a catalog.
If this functionality is necessary when using Glue, please set
FEATURE_UI_ENABLE_LEGACY_REGISTRATION_PAGE: truein your Okera configuration, which will use the prior version of the Data Registration UI. - Databases created through the Okera UI can no longer start with an underscore.
- Okera's Presto proxy will require a minimum TLS version of 1.2 by default.