Active/Active Deployment in Aurora RDS¶
You can run multiple Okera clusters in separate regions that share data using an Amazon Aurora relational database service (RDS) with write-forwarding enabled. Consider the following Aurora RDS environment:
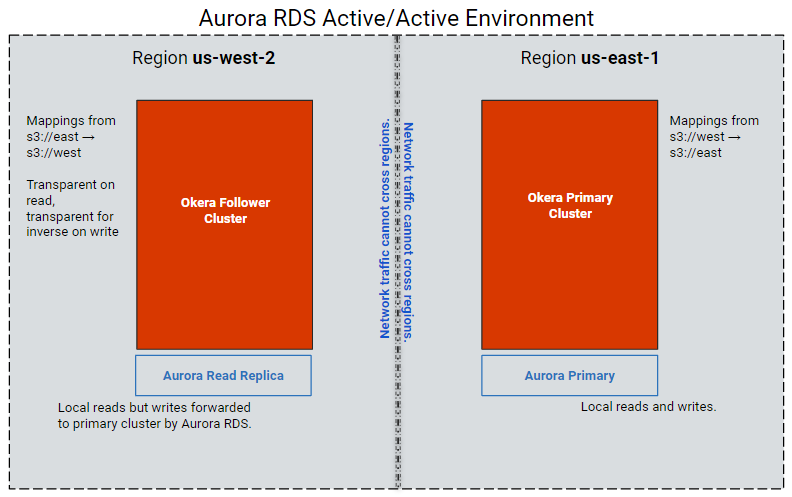
In this example, we show one Okera cluster with a local Aurora relational database in region us-east-1 and a replica cluster with a local Aurora relational database in region us-west-2. Aurora RDS is used to synchronize updates between the relational databases in each region.
The cluster in each region communicates with its local read-only database. Aurora RDS synchronizes updates between the primary instance and its replicas in each region. This environment allows multiple active Okera environments to share data and is called an active/active environment.
In an active/active environment, a single Okera cluster must be identified as the primary cluster. The replica clusters are followers of the primary cluster. The number of followers is unlimited, but for simplicity, the examples in this documentation use only two clusters: a primary cluster in region us-east-1 and a single follower cluster in region us-west-2.
Configure the Active/Active Environment¶
To configure your Okera clusters to support an active/active configuration, follow these steps.
- Create mapping files that identify the Amazon S3 source and destination buckets for each cluster.
- Update the Okera configuration files with specific configuration parameters.
- Restart Okera in each region.
Create Mapping Files¶
An active/active mapping file in JSON format must be created for each cluster. The mapping files identify the Amazon S3 source and destination buckets specific to each cluster, depending on whether the cluster is the primary cluster or a follower cluster.
Note: Okera highly recommends you use canonical names for your clusters in the map files. This will simplify mapping updates should you need to change your cluster IP addresses later.
Primary Cluster Mapping File¶
In the mapping file on the primary cluster, the source bucket should always be the follower Amazon S3 bucket, and the destination bucket should always be the corresponding primary cluster Amazon S3 bucket. For example, in our us-east-1 and us-west-2 cluster scenario where the us-east-1 cluster is the primary cluster and the us-west-2 cluster is the follower, the following mapping file would be used for region us-east-1:
{
mappings: [
{
src: "s3://us-west-2/marketing",
dst: "s3://us-east-1/marketing"
},
{
src: "s3://us-west-2/engineering",
dst: "s3://us-east-1/engineering"
}
]
}
Follower Cluster Mapping File¶
In the mapping file on the follower clusters, the source bucket should always be the primary cluster Amazon S3 bucket, and the destination bucket should always be the corresponding follower cluster Amazon S3 bucket. For example, in our us-east-1 and us-west-2 cluster scenario where the us-east-1 cluster is the primary cluster, the following mapping file would be used for region us-west-2:
{
mappings: [
{
src: "s3://us-east-1/marketing",
dst: "s3://us-west-2/marketing"
},
{
src: "s3://us-east-1/engineering",
dst: "s3://us-west-2/engineering"
}
]
}
Okera Configuration File Changes¶
The following Okera configuration file parameters should be specified in the Okera yaml configuration file.
-
IS_FOLLOWER: This configuration parameter indicates whether the cluster is a follower cluster. Valid values for this parameter aretrueorfalse. The configuration file for the follower clusters should set this parameter totrue. The configuration file for the primary cluster should set this parameter tofalse. -
PATH_PREFIX_MAP_FILE: This configuration parameter identifies the location of the mapping file for the cluster. The Okera cluster must be able to access this location and read it at startup. -
APPLY_INVERSE_MAP_ON_WRITE: This configuration parameter indicates whether the cluster should invert the bucket names when a write is attempted on a follower cluster. Data is usually written to the primary cluster. If you want to write data in a follower cluster, the mapping must be inverted to ensure that an attempt to write the data across regions does not occur.Valid values for this parameter are
trueorfalse. The configuration file for the follower clusters should set this parameter totrue. The configuration file for the primary cluster should set this parameter tofalse. -
SYSTEM_DB_CONNECTION_URL_SUFFIX: This configuration parameter is a global Aurora RDS setting that enables Aurora RDS to perform write forwarding. Since Aurora does not persist this setting, Okera passes it as part of the connection string. This parameter should always be set like this as an environment variable on the follower clusters:SYSTEM_DB_CONNECTION_URL_SUFFIX: sessionVariables=aurora_replica_read_consistency=’session’No other values are allowed. This parameter should not be set on the primary cluster.
Primary Cluster Configuration File¶
The following is an example of the configuration settings in the primary cluster configuration file.
IS_FOLLOWER: false
PATH_PREFIX_MAP_FILE: <path to primary cluster mapping file>
APPLY_INVERSE_MAP_ON_WRITE: false
Follower Cluster Configuration File¶
The following is an example of the configuration settings in the configuration files for all follower clusters.
IS_FOLLOWER: true
PATH_PREFIX_MAP_FILE: <path to follower cluster mapping file>
APPLY_INVERSE_MAP_ON_WRITE: true
SYSTEM_DB_CONNECTION_URL_SUFFIX: sessionVariables=aurora_replica_read_consistency=’session’
Failover Changes¶
If your primary cluster goes down and you need to use one of your follower clusters as the primary cluster, make the following changes:
-
Use the AWS Console to configure the Aurora instance as the primary instance. This must complete prior to reconfiguring the Okera cluster in the next step, because the primary cluster must have write access to the RDS to ensure the cluster starts properly.
-
Edit the Okera configuration file of the follower cluster and make the following changes:
- Change the
IS_FOLLOWERparameter setting tofalse. - Delete the
SYSTEM_DB_CONNECTION_URL_SUFFIXsetting from the file.
- Change the
-
Restart the Okera follower cluster to convert the follower cluster to the new primary cluster.
Active/Active In-Parallel Policy Loading¶
Okera performs in parallel policy loading when active/active environments start up. This speeds up service start time, particularly for slower RDBMS environments or environments in which many roles must be loaded. Okera uses two thread pools to perform active/active in-parallel policy loading, one for the initial load and one that occurs in the background. The default number of roles loaded in parallel for an initial load is 12; the default number of roles loaded in the ackground is 2. To control these settings, use these configuration parameters:
SENTRY_INITIAL_LOAD_THREADScan be used to override the initial load default. Specify the number of roles that should be loaded in parallel when an active/active environment is initially started.SENTRY_BACKGROUND_LOAD_THREADScan be used to override the background load default. Specify the number of roles that should be loaded in parallel in the background of an active/active environment.