Cluster Component Overview¶
Okera is a scalable, fault-tolerant distributed service for data consumers, such as analytics tools, to interact with. Okera performs the I/O and provisions data to third-party tools after applying schema, fine-grained security, and other transformations (user-defined functions, tokenization, masking, and so forth). The data is provisioned in the form of familiar abstractions, which is either as tables or as files in formats the user may request.
Clients communicate with an Okera cluster using the provided APIs and libraries, explained in the Okera Policy Engine Integration and Client Integration documentation.
Finally, the functionality provided by Okera is extensible, as described in the Extending Okera documentation.
Okera Services¶
In order to perform its duty, Okera is made up of the following micoservices and components. The more detailed Architecture Overview explains how all of the Okera Platform microservices work together.
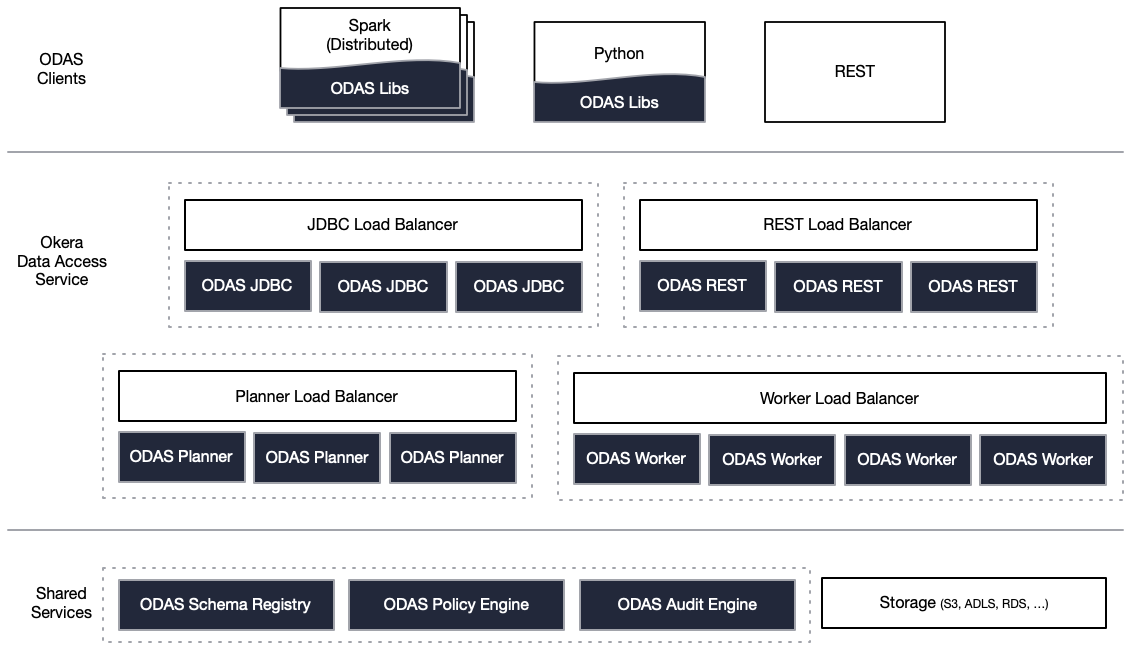
Client Integrations¶
It is a common pattern that clients use analytics applications, such as Business Intelligence tools (for instance, Tableau, MicroStrategy, or Power BI), or compute engines (for example, Amazon EMR, Databricks, or Presto) to process their data. Okera provides well-supported APIs, such as REST or JDBC so that these tools and frameworks can access data protected by Okera with little to no change.
Alternatively, and for a more immersive experience, users can also have their tools and frameworks provisioned with Okera-provided client libraries, which seamlessly connect to their Okera clusters. For instance, using PyOkera combined with a Python based data science tool like Jupyter, users can transparently access their data while Okera is enforcing all access policies behind the scenes.
Okera Policy Engine (Planner)¶
Before a query, or more generically speaking a read operation, is executed, the clients send the details about the operation to the Okera Policy Engine services endpoint - which is typically distributed behind network load-balancing appliances. Okera Policy analyze the operation and compute the best execution path, which includes decisions such as:
- What policies apply to the current client wishing to execute the operation?
- What objects are part of the operation and what storage service is providing them?
- What parts of the operation can be managed directly inside the storage service?
- How can the operation parallelized across the Okera cluster (if necessary) or the underlying storage service?
The end-result is that Okera Policy Engines return an optimal execution plan, which strikes a balance between being as least intrusive as possible to maintain the query performance users are expecting, while inserting Okera functionality only as much as the policies require. This means, for example, that one operation is purely executed within the original storage service, with the query rewritten to apply the Okera-defined policies. And in another case, for instance, an operation may require for the Okera Enforcement Fleet to read and parse the data, so that the policies can be applied. More on this below.
Okera Enforcement Fleet (Workers)¶
This sub-service does the heavy lifting, that is, read, (optionally) transform, and deliver data from the pluggable storage layer to the clients.
The following diagram shows how a single, shared Okera cluster is connecting the raw storage layer with the clients.
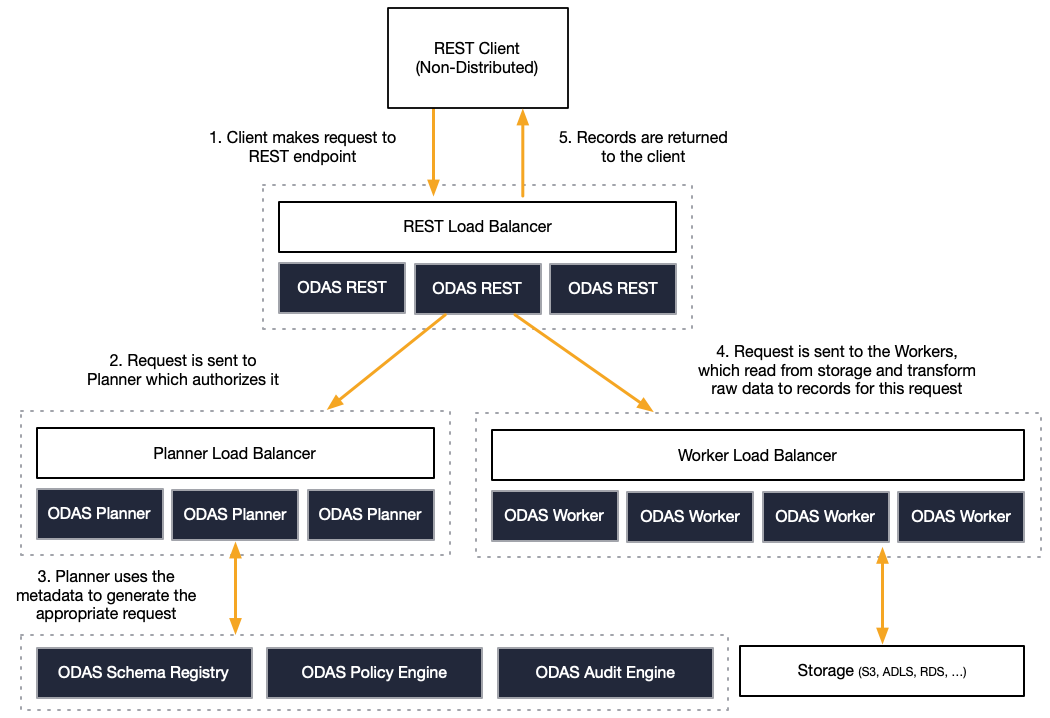
The workers use the Okera Catalog services to apply schemas to registered datasets, as well as the role-based access control. Data read from the storage services is being streamed through the Worker nodes to the client so that the memory requirements on the servers they run on is low. One advantage of this is that workers can cache hot data (such as a lookup or dimension table) so that concurrent access is accelerated for subsequent queries.
Note that workers are only used when the Okera Policy Engine decides this being the best course of action given the query details.
Basic Deployment Options¶
An Okera installation can include multiple instances of Okera running in your data environment. Some may be ephemeral, while others may be persistent. Some may be running as independent services whereas others may be collocated with the analytics framework. The deployment model depends on the performance and isolation requirements.
The following diagram shows a layout with multiple Okera instances running, governed by a single set of Okera Metadata Services.
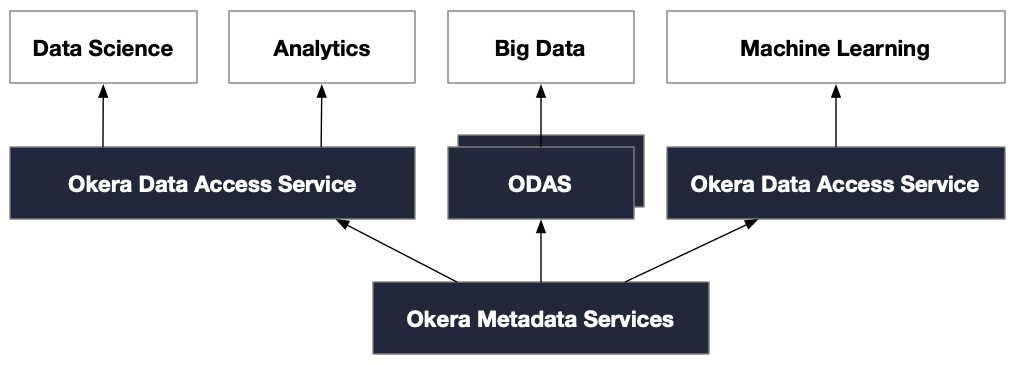
More on deployment option and architecture can be found in the architecture section.