Schema Design¶
Goal and Audience¶
This document is for DBAs, developers, and data architects who are trying to understand the schema design adjustments necessary when working with the Okera Platform.
Introduction¶
As shown in the Architecture Overview, the Okera Platform is a distributed, scalable, efficient, and high performance data access system, which includes a Schema Registry that maps raw data into tables. While these schemas can be arbitrarily complex, not all of the functionality should be delegated to Okera, but rather some should be handled in more specific clients, such as SQL engines. For additional information on external views, please refer to the Supported SQL documentation.
Layers¶
In working with Okera, it is recommended to adopt a specific design approach when defining datasets. You should think of schemas in terms of the following layers:
- Physical Layer
- Base Table Layer
- Cleanup View Layer
- Access Control Layer
The diagram below shows this in greater detail and we will discuss the layers in the next sections.
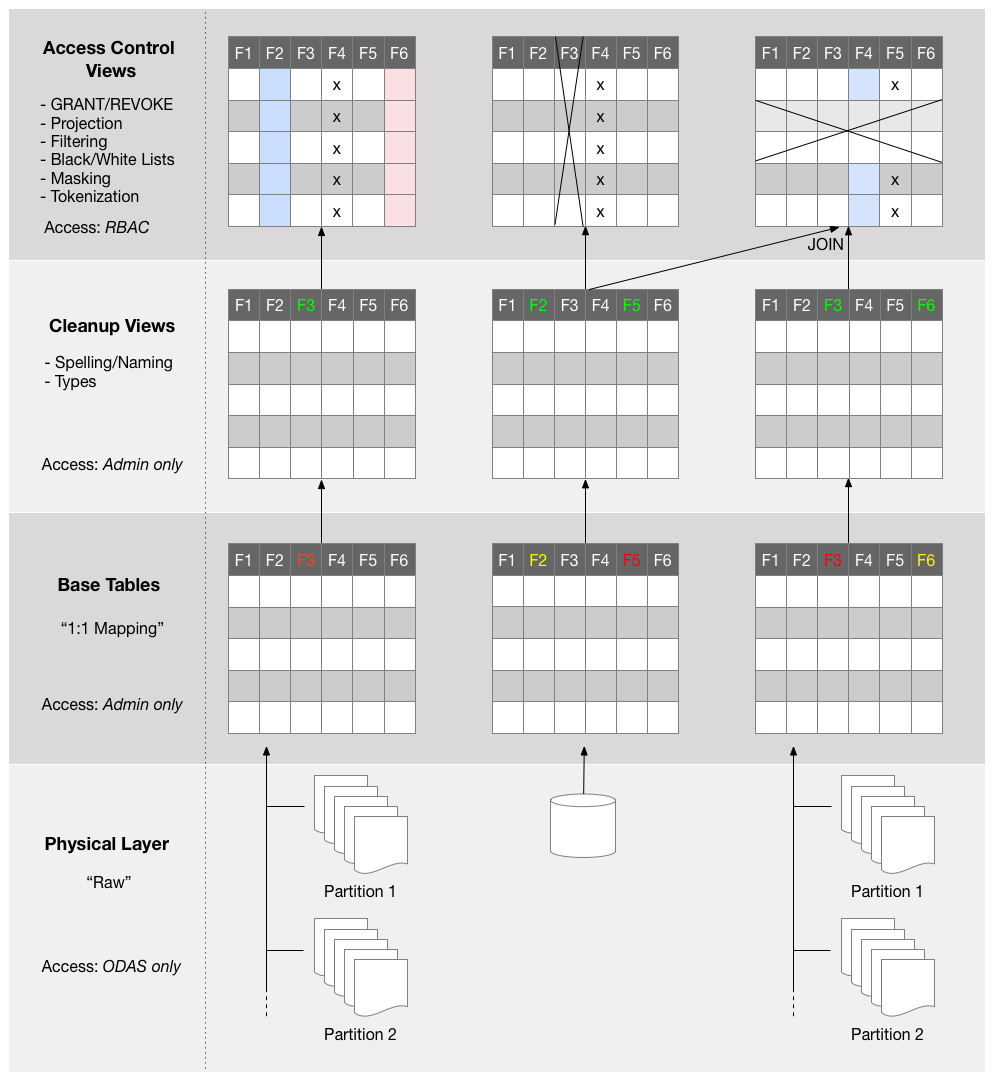
Physical Layer¶
The physical layer consists of storage in its raw format as files on Amazon S3 or HDFS, or as a database table in an RDBMS. For file-based storage, there is usually one or more files in one or more directories. The latter may convey special meaning, such as partitions supported by Hive.
It is important to note that in order to ensure data access and governance policy enforcement, the Okera Platform and administrators should be the primary user to this layer.
Base Table Layer¶
The base table layer defines the first set of metadata by mapping the raw data, as-is, into Okera's Schema Registry. Only tables are defined at this level and are referred to as base tables. Their schema comes directly from the source retaining all the naming and data type declarations.
Example: Creating an external base table over the raw data
CREATE EXTERNAL TABLE sales.transactions_raw(
txnid BIGINT,
field_87 STRING,
field_06 STRING,
field_12 STRING,
field_73 STRING,
field_33 STRING,
ip STRING)
COMMENT 'Raw online transactions'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LOCATION 's3://sales-data/transactions';
You may note that some fields are arbitrarily named and all of them are defined as type STRING.
In this example, we assume that some fields are of a non-string type.
While still a valid statement, this CREATE statement is not ideal for direct querying.
Access to these base tables is restricted to Okera administrators (or by someone granted administrative rights). No direct access by any user or application is allowed.
Cleanup View Layer¶
The cleanup view layer is an applied view on top of the base table defined to fix any immediate table issues. In continuing with the example, we can reorder fields to comply with some company policies, cast the field types, and rename arbitrary fields into readable names.
Example: Creating a cleanup view over a base table
CREATE VIEW sales.transactions_clean AS
SELECT txnid,
field_12 AS dt_time,
field_33 AS sku,
cast(field_87 AS INT) AS userid,
cast(field_73 AS FLOAT) AS price,
field_06 AS creditcard,
ip)
FROM sales.transactions_raw;
There is a strict 1:1 mapping between base table and cleanup view. There are no JOINs performed at this level; only schema transformations.
No user will be given access to the sensitive data in cleanup views; only dedicated staff, such as administrators or data stewards are allowed access. In the case of cleanup views that contain only publicly accessible data, it is permissible to grant direct access to non-administrative users as well.
Access Control Layer¶
The access control layer is the final layer where we provision user access to the data using access policies.
We have only implicitly dealt with the Okera Schema Registry thus far.
This service is responsible with storing the platform-wide dataset metadata.
Next, we will allow access to those datasets through the Okera Policy Engine in the form of GRANT statements.
All access to databases and datasets (commonly referred to as objects) is assigned to arbitrary roles.
These roles are then assigned to groups of known users, enabling the so-called role-based access control.
The user groups are provided using a variety of sources, including Active Directory (AD), Lightweight Directory Access Protocol (LDAP), and JSON Web Token (JWT).
The next example creates the analyst role and assigns it to a user group.
Example: Creating a role and assigning it to a user group
CREATE ROLE analyst_role;
GRANT ROLE analyst_role TO GROUP analysts;
Continuing with the example, we can define a new attribute-based access control policy over the cleanup view created in the previous section to grant access to this new dataset, with tokenization and masking functions applied on the sensitive data. Note that within Okera's Policy Engine, access is additive and no one has access to data unless explicitly granted access.
Example: Creating an access policy giving read-only access to our newly created role on the cleanup view of the transactions dataset, with masking and tokenization applied to columns with certain sensitive data tags on them. Note the example below assumes that the pii.userid pii.ip_address and pii.credit_card tags have been assigned on the relevant sensitive columns. For more information please read ABAC.
GRANT SELECT on table sales.transactions_clean
TRANSFORM IN (pii.userid, pii.ip_address) WITH tokenize()
TRANSFORM pii.credit_card WITH mask_ccn()
TO ROLE analyst_role;
Note: The examples show Hive QL syntax. Hive does not distinguish between Okera views or tables, which is why the
GRANTstatement is on a table instead.
The above example provides an overview of schema design best practices. While your organization's needs may vary, these steps give the best framework to create and manage data through the Okera Platform.