Upgrade Okera¶
After deploying an Okera cluster and operating it for some amount of time there will eventually be the need to upgrade it to a newer Okera release, since newer versions are likely to contain new features that become important to the business.
This topic walks you through the general process of upgrading an existing Okera installation. Before we start, here are a few important notes:
- We assume that Okera is deployed using a managed Kubernetes service. This may be in a private or public cloud environment, including self-managed Kubernetes clusters on-premises.
- In practice, there will be more than one Okera cluster installed within an organization, driven by the common software engineering lifecycle. This includes (but is not limited to) dedicated setups for development, testing, integration testing, user acceptance testing, pre-production, and production. These setups typically vary in the size of the installation, but not in the general architecture. In other words, they may use smaller instance types for the machines used, but still rely on services provided by dedicated infrastructure (for example, there will be a separate database management system). For this tutorial we treat each of them the same, that is, the described steps apply to each setup the same way.
Important
Okera recommends that you back up your database (take a database snapshot) before you upgrade.
Dependencies¶
An Okera cluster commonly sits between sources and consumers of data. All of the cluster state is handled by the metadata services, including the Schema Registry, Policy Engine, and Audit Engine. The following diagram shows this at a very high level.
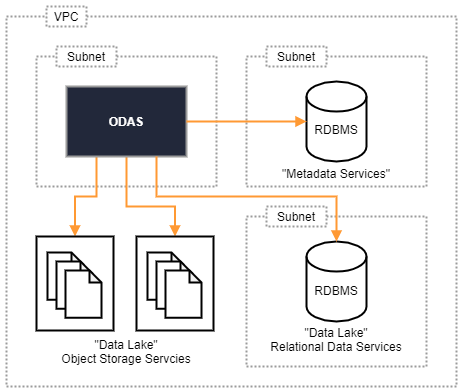
When considering an Okera cluster update, the shown dependencies need to be included in the planning. These considerations apply:
-
Metadata Services - Every Okera cluster needs a way to persist its metadata, which includes database and dataset details, such as originating data source, column schema, data parsing information, and more. It also includes all of the access policies and object attributes. There are a handful of databases that an Okera accesses in the configured RDBMS. These databases and their tables are sometimes updated, where tables are added or removed, or existing tables and views are updated to support new functionality. This means that across major updates there is a likely chance for the metadata databases to have schema changes applied. As documented in the Release Notes these changes may be not backward compatible. This will require careful planning when updating an Okera cluster, which is discussed below.
-
Log Storage - When operated and configured as recommended by Okera, each Okera cluster persists its operational and audit logs as files to a storage service (such as Amazon S3, ADLS, or GCS). The files are arranged by type and (for audit logs) partitioned by date. They drive Okera services such as Okera insights, as well as (optional but very useful) external services, such as search engines that digest log information fast and efficiently. When updating an Okera cluster, the operations team needs to be aware of the change and ensure a smooth transition from the existing cluster to the new one, providing consistent access to the old and new log information.
-
Source Services - In practice, a data lake usually comprises a polyglot set of storage services, such as file and/or object services (such as Amazon S3 or ADLS), and/or relational data services (such as MySQL, PostgreSQL, or Snowflake). When upgrading an Okera cluster, it may be necessary to adjust for new features provided by Okera in the process. For instance, the support of specific schema options, including complex, or nested, types. Adopting new features may have a significant impact and warrant a change for existing schemas.
Upgrade Strategy¶
Okera recommends you perform an upgrade in a blue-green deployment fashion, that is, deploy a different version of Okera on a new cluster, while retaining the old one until all testing has been completed and all clients have been transitioned to the new cluster. The steps to perform an upgrade using this approach can be described in the following steps.
-
Back up your Okera database (take a database snapshot) before you upgrade.
-
Set up secondary metadata databases - Assuming you perform regular backups if the databases serving the Okera metadata services, restore a (recent) backup of all databases, either with their same names on a different RDBMS instance/service, or with different names on the existing RDBMS instance/service.
-
Provision new Okera cluster - Deploy the different version of Okera chosen to a new set of infrastructure resources, namely new virtual machines or servers. Keep in mind that this instance needs to be able to talk to the above secondary metadata databases, and also to the storage systems that need to be tested. You also need to ensure that clients can access this cluster using their client software, such as BI tools for ad-hoc queries, or compute engines for analytical processing jobs.
-
Apply changes and perform testing - As discussed above, based on the changes between the Okera versions, consider which features you want to adopt or phase out and apply those changes to the new cluster. Then perform all the testing needed to ensure that the new cluster is able to handle the existing workloads.
-
Move clients to new cluster and phase out the old one - Once testing is successful, start to migrate use-cases over to the new cluster while cross-checking that everything works as expected. In this stage it is still possible to go back to the old cluster in case of some unexpected problems that need to be addressed first.
-
Shut down old cluster - When all users have been transitioned to the new cluster and some grace period has passed, the old cluster can be terminated and the old databases containing its metadata can be dropped (or the entire RDBMS instance terminated if it is not needed anymore).
There are a few notes that apply to the above steps:
-
Syncing metadata changes - When operating two distinct sets of databases for the metadata, it may be necessary to sync the changes from one to the other. This needs to be handled from the application side as Okera cannot enforce such a synchronization without user support. There are few ways to mitigate this process: When the database schemas are not changing between the Okera versions, you could decide to point both instances at the same databases. In addition, you could optionally use distinct database users within the RDBMS and restrict one of the versions to only read from the databases, avoiding inadvertent changes to the metadata. If you are required to use two separate sets of databases, you can also use the audit logs of the Okera instances to query all DDL (and DCL) statements that have been applied in some time frame. These statements could then be applied to the other instance in a bulk fashion to replay the changes when needed.
-
Replaying logs - For testing the above approach of extracting statements from the audit logs is also a viable option to not only see what type of queries users or applications run, but also to test the same queries on the new Okera instance. For more performance related testing, this assumes that both cluster instances have been provisioned with equal resources, and have access to the same source data that is accessed by the queries. Given that the Okera Policy Engine (planner) audit logs also contain the time when the query was sent, the execution of the queries on the new cluster could be timed in the same manner to compare the cluster performance. For more advanced comparison, the Okera Enforcement Fleet worker audit logs could be compared between the clusters to see long a query ran in total, using the query ID field of the logs.
-
Updating infrastructure - Updating an Okera cluster also may open an opportunity to update the underlying infrastructure. For example, setting up a new RDBMS instance may allow deploying the latest approved version of it. The same applies to managed Kubernetes services, which use a specific version of the Kubernetes control plane, and setting up a new Okera cluster may allow switching to the latest approved Kubernetes version of it.
Summary¶
Upgrading an Okera cluster requires common infrastructure skills that are also required by many other applications. Proper planning of the upgrade process, including the assessment of its impact on dependent systems, is key to being successful in rolling out a new Okera version. Since Okera is full containerized and is relying on common RDBMSs for storing its state, the upgrade process is akin to that of other transactional systems.
Using a blue-green deployment approach lends itself well to this process, as it is easy to deploy new machine instances in a managed infrastructure. Being able to test old against new, perform regression testing and run performance tests, and migrate use-cases at a sustainable pace is further validating the upgrade approach.
As usual, the Okera Customer Success team is there to support you and help you plan this process. Feel free to reach out and plan this jointly with your Okera account manager!