Hive Integration - Best Practices¶
Goals and Audience¶
This document describes best practices for using Hive with the Okera Platform. The target audience is architects, developers, and database administrators (DBAs).
Introduction¶
Apache Hive is a library that converts SQL (to be precise, Hive SQL) into processing jobs that can be executed by various Hadoop-provided backends. This includes Apache YARN for batch processing, and Apache Tez for more ad-hoc queries. Processing consists of the following steps:
- HiveQL is submitted to Hive by the user (using, for example, the Hive CLI)
- The Hive client parses the query and plans the request, which includes:
- Contacting the Hive metastore to get the metadata for all contained tables and views in the query
- Computing a plan that expresses the query actions (such as aggregations, filters, and data scans)
- Optimizing the query based on (optionally) available statistics
- Determining resource requirements, based on data locality and query parallelism
- With the plan completed, the Hive client starts a job with those resource requirements in the configured processing backend
- The processing starts within the framework resulting in one or more stages of the query actions to run concurrently
- Intermittent (as in temporary) data is swapped to disk or cached in memory, depending on the engine that runs the query
- All resulting data is persisted or streamed to the client for final delivery
While some of these steps in the planning phase are very similar to what is done by an RDBMS when executing SQL queries, there is quite a difference in the execution phase. This manifests itself in the need to understand the underlying engine and how its stage execution can affect the overall query performance.
This is no different than running a well-written or badly written MapReduce or Spark job: when the job is not using the framework efficiently, the overall outcome is suboptimal. For this reason, using Hive mainly revolves around writing queries in such a way that it performs as expected. This includes making a conscious decision about:
-
Data Types - As with regular databases, favor numeric types, where possible, over costly types like
STRING. -
Partitioning - Large file system-backed datasets must be partitioned by one or more column value, for example a date or geographical region, to ensure the underlying data is grouped into smaller files. In combination with specific SQL
WHEREclauses, this enables more efficient querying by eliminating unnecessary data files altogether, referred to as partition pruning. The number of partitions for a table should not be too high, that is, in excess of 100,000 partitions. It should also not be too low and, for example, cause each partition to contain tenths of a gigabyte of data or more. The goal is to have a few hundred megabytes per partition. For date-based partitioning, in most cases, day-level partitions work very well. -
File Formats - Okera recommends that you use a binary, block-based file format (when using a file system backend such as HDFS or Amazon S3). Depending on the use case, the choice in practice is between Avro (for row-based access use cases, such as batch-oriented full dataset scans) or Parquet (for column-based use cases, such as highly selective analytics). Text-based file formats are not ideal as they require more resources for parsing the text into binary objects.
-
Compression - Most datasets contain data that compresses well, reducing the necessary I/O operations needed to read the data. The extra cost of decompression is often negligible as systems are bound by other low-level resources first (such as networking or storage I/O). If the data is not already compressed, enabling block-based compression for the above file formats is recommended as a default. For processing engines that spill intermediate data to disk, Okera recommends that you enable data compression as well as a suitable binary file format.
-
Block Size - A common optimization for large-scale data processing is to read larger chunks of data from the same execution task. One reason is that starting up executors is a relatively slow operation (especially for YARN-backed processing), and another is that I/O is faster if data is transferred in contiguous chunks of reasonable size, referred to as streaming reads. For example, a block size could be set to 256MB and is read in chunks of 16KB.
-
Combine/Split Files - Engines that read data from files can be configured to combine smaller files or split larger files to even out the perceived block sizes from the executor tasks.
In general, these decision points are the same with Okera, since the Okera Enforcement Fleet (workers) perform the same operations for I/O.
Impact of Okera¶
Adding the Okera Platform in many ways does not change this pattern.
In fact, you can think of Okera's Okera as another table (or view) on top of raw data.
Complex queries that contain analytical functionality, such as the use of DISTINCT and GROUP BY, are neither allowed nor supported, in Okera.
Instead, Okera uses SQL DML only to enable efficient access control expressed in a common syntax.
The greatest impact of introducing Okera to an existing Hive stack is the change in schema design and the setup of the Hive metastore used for the Okera schema registry.
Schema Design¶
Okera recommends the use of a layered schema design, which mitigates schema drift issues of the raw data source by decoupling the users from those resources. The layers are (explained from the bottom to the top):
-
Raw Tables - All registered datasets are represented as-is by a TABLE object. This means the original schema of the underlying data source is mapped into the Okera schema registry without any modification.
-
Cleanup Views - Any structural modifications are covered by this layer. The views wrap the raw tables one-to-one but are used to rename fields, cast types to appropriate ones, and fix column values (for example, remove a technical prefix that is obsolete). No filtering through the use of
WHEREclauses or combining of tables is allowed. The cleaned views form the entry-level object layer for data consumers. See Schema Evolution for more information about how this layer helps to protect users from changes. -
Access Control Views - This layer adds any access-related processing, including the use of functions to mask or tokenize column values, filtering using
WHEREclauses (for example, filter all rows based on geography) orJOINstatements. Access control is not needed for all datasets, making this layer optional. For example, public datasets that can be accessed by all authenticated users do not need an access control view. -
External Views - For any query that contains unsupported SQL functionality, such as aggregations for analytical processing, the
EXTERNALkeyword can be used during the definition of a VIEW to cause its evaluation to occur in the downstream processing engine (which is not just Hive, but also Spark and similar tools). See the External Views section for details.
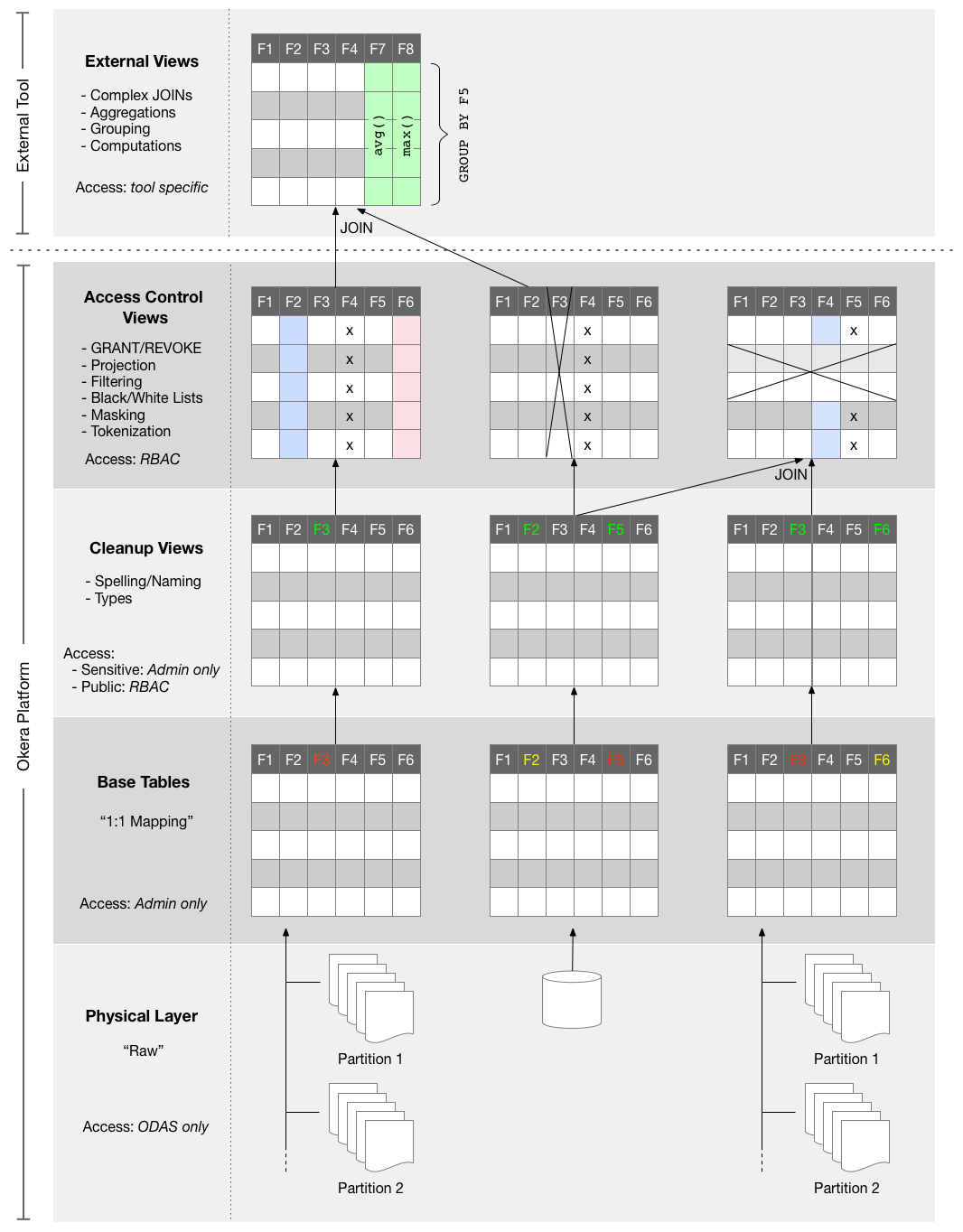
Defining those views over the base table is not costly, since the Okera Platform is evaluating them at query plan time. In other words, the operations of each view over the base table are combined into a single SQL statement, complete with user role-dependent actions. When the query is executed on the Okera workers, there is no further cost to the slightly more involved schema hierarchy. Essentially, it is free of any overhead.
With this approach you have a schema design architecture that accomplishes the following:
- Protects from schema evolution of the ingested data
- Allows cleanup of raw table structures
- Enables efficient and comprehensive access control
- Leaves the execution of compute-intense operations to downstream engines
- Avoids adding overhead during query execution time
Okera recommends following these guidelines to provide for reliable and future-proof metadata management.
Schema Evolution¶
Should the structure of the external data source change (that is, the raw table schema changes), adjustments can be made in the cleanup views. This way, the raw table structure is disconnected from the users, so that low-level changes are only reflected in the view definition: all downstream consumers can use the view as they did before, avoiding the need to react to any schema change immediately.
Of course, the view may not be able to disguise substantial changes in the raw table structure. In such cases, a new VIEW can be defined with a new name.
Users who need access to the latest schema can migrate to the new view at their own convenience.
External Views¶
The way views are defined determines how they are evaluated.
For example, consider this VIEW definition:
CREATE VIEW sales_transactions_cal
AS SELECT <fields> ...
FROM sales_transactions
WHERE region = 'california'
Note: The base
sales_transactionsdataset is assumed to be an access control view.
Usually, when a user query is containing such a view, (for instance, SELECT * sales_transactions_cal), the Okera Policy Engine (planner) returns the VIEW as a TABLE definition (that is, it returns the fields in the final schema) when asked by the compute framework.
This can be emulated using the SHOW CREATE TABLE command from the Hive CLI (ignoring the remainder of the output):
hive> SHOW CREATE TABLE sales_transactions_cal;
OK
CREATE EXTERNAL TABLE sales_transactions_cal(
txnid bigint COMMENT '',
dt_time string COMMENT '',
sku string COMMENT '',
userid int COMMENT '',
price float COMMENT '',
creditcard string COMMENT '',
ip string COMMENT '')
...
This leaves the framework no choice but to read from the (pseudo) table as if it is a raw source of data (such as an Amazon S3 file).
Okera supports the EXTERNAL keyword to define a view that is different from this default behavior.
For example:
CREATE EXTERNAL VIEW revenue_cal
AS SELECT min(revenue) as minRevenue, max(revenue) as maxRevenue
FROM sales_transactions
WHERE region = 'california'
The view uses an aggregation function that is not supported by Okera itself.
The EXTERNAL keyword changes how the Okera Policy Engine returns the VIEW definition when asked by the compute framework, returning the full VIEW definition instead:
hive> SHOW CREATE TABLE revenue_cal;
OK
CREATE VIEW revenue_cal AS SELECT * FROM salesdb.sales_transactions
WHERE region = 'california'
This causes the evaluation of the VIEW to occur outside of Okera and inside the downstream compute framework instead.
All of the unsupported SQL is handled downstream as well, while the source of the VIEW, here the sales_transaction access control view, is still handled by Okera, applying filtering and audit logging as expected.
Default Partition Pruning¶
DBAs have more options using layered views in Okera, allowing them, for example, to limit the amount of data returned from a partitioned table when no matching WHERE clauses were defined.
The LAST PARTITION feature avoids unnecessary full table scans that might exhaust valuable system resources (for example, issuing SELECT * FROM <table_or_view> to identify the data in a dataset that contains terabytes or petabytes of data).
This feature is very flexible and allows you to specify how many data files or how many partitions should be read. For example:
CREATE VIEW sampledb.ymdata_recent AS
SELECT * FROM sampledb.ymdata(LAST PARTITION);
CREATE VIEW sampledb.ymdata_last_file AS
SELECT * FROM sampledb.sample(LAST 1 FILES);
CREATE VIEW sampledb.ymdata_last_4_months AS
SELECT * FROM sampledb.ymdata(LAST 4 PARTITIONS);
This is also applicable to the raw tables, using table properties:
ALTER TABLE sampledb.tbl_ds1_last_1 SET TBLPROPERTIES(
'okera.default-last-n-partitions'='1')
Okera recommends using partition pruning on large tables with more than 100 partitions.
For more information, see Supported SQL.
Writing Data¶
Hive supports multiple SQL statements to write data back into datasets. These are:
-
CREATE ... TABLE ... <table> ... AS SELECT ... FROM ...Using one statement, you can create a new table and fill it with data returned by the specified query.
-
INSERT OVERWRITE TABLE <table> ... SELECT ... FROM ...This statement can be used to replace a partition or entire table with data generated by a given query.
-
INSERT INTO TABLE <table> ... SELECT ... FROM ...Instead of replacing data, this statement appends data from the specified query to the named table or partition.
-
INSERT INTO TABLE <table> ... VALUES ...This statement is the same as provided with regular relational database management systems, where concrete values are inserted into an existing table. In practice, this is used mostly to generate (small) test data.
All of these queries require access to the underlying storage location of the dataset. With Okera, you have two choices to handle these types of operations:
-
Use a local filesystem.
In this case, all writes bypass Okera altogether. This is useful for sandboxing or temporary staging of data on compute clusters, using a cluster-local filesystem, such as HDFS on ephemeral disks attached to the virtual machines. This solution is ideally suited for temporary datasets that have the same lifetime as the compute cluster.
-
Use a shared filesystem.
In this case, the Hive queries write data to a shared filesystem, such as Amazon S3 or Azure Blob Storage (WASB). The queries could be executed by a real user or a technical user that executes a pipeline.
Notes: - For both options, you must have write access to the underlying storage systems. - For option 2, you also must have ALL or INSERT permissions granted in the Okera Policy Engine.
For shared filesystems, two modes of operation are supported. They are controlled by the setting of the boolean configuration variable
okera.hive.allow-original-metadata-on-all-tables in the hive-site.xml file. Valid values are true or false, with a default of false:
-
Allow original metadata (variable set to
true)When the variable is
true, Okera enables writes to partitioned and non-partitioned tables. This exposes the underlying metadata of non-partitioned tables to clients, which disables their fine-grained access control. Partitioned tables are still fully controlled for reads. -
Do not allow original metadata (variable set to
false)When the variable is
false(the default mode), the metadata for non-partitioned tables is not exposed. The non-partitioned tables cannot be written to and fine-grained access control for reads are enabled. For partitioned tables, both read and writes are possible.
Note: Okera currently only supports writing to file systems (based on Hadoop's
FileSystemimplementation). In other words, JDBC writing is not supported.
The following table summarizes the read and write support for either mode.
| Mode | Partitioned Table | Non-Partitioned Table |
|---|---|---|
true |
Read & Write | Write |
false (default) |
Read & Write | Read |
Depending on the existence of both table types, or only one of them, the administrator can select the required mode when writes are necessary.
In practice, the reason to read or write data is manifold. The following diagram shows a common scenario, where data producers write authoritative (full fidelity) data into the storage systems. These are usually privileged processes that run as part of automated data pipelines. As such, they have elevated rights to read and write directly from and to the storage systems.
On the other hand, data consumers run their own compute resources to analyze the data. Reading the data is fully controlled by the Okera Policy Engine, ensuring fine-grained access control is enforced as expected. Consumers can still write data into storage systems (for example, persisting intermediate or resulting data) but do so with regular permissions and into separate storage locations.

Hive Metastore¶
When you set up the Okera platform, the default settings assume that Okera is responsible to run and maintain the metastore, which drives the schema registry.
Hive Configuration¶
The online client documentation lists the possible configuration settings for Hive. The troubleshooting section below uses some of those settings to address common issues.
Note: You must enable the Hive client integration provided by Okera to get fully seamless functionality with an Okera cluster.
Distributed Filesystems¶
For cloud-based Hive setups, such as Amazon EMR, Okera recommends you use the accompanying distributed file or object service, that is, Amazon S3. In general, you need to ensure data is kept persistent and is not stored in ephemeral storage that is deleted when the compute cluster is deleted.
Okera also recommends that you configure the persistent storage system as the default Hive warehouse directory.
This can be set in the hive-site.xml configuration file.
Example: Changing the default table locations to an Amazon S3 bucket
<property>
<name>hive.metastore.warehouse.dir</name>
<value>s3://<bucket>/warehouse</value>
</property>
Local Filesystems¶
For Hadoop clusters, such as Amazon EMR, there may be a local filesystem available (usually HDFS) that can be used for specific purposes. For example, the cluster-local filesystem can be used to experiment with data and processing jobs that completely bypass Okera. This is recommended by Okera for the development of user-defined functions (UDFs), since it does not require any premature registration with the Okera Platform and allows for easy replacement of the resources (that is, the Java JARs).
Note: Since the Okera Platform is bypassed, no access control and audit event logging is performed. Only use the cluster-local filesystem for non-sensitive data (such as anonymized test data), or ensure that the cluster is otherwise properly secured.
See the Amazon EMR documentation and Developing Functions for details.
Troubleshooting¶
In practice, adding Okera to an existing environment changes some of the behavior of queries. Some known issues are described below.
Okera Policy Engine (Planner) Timeouts¶
For file system-based datasets, if no default partition pruning is set and a user is running a full table scan (for example using SELECT * FROM <table_name>, the Okera Policy Engine needs to check the metadata of any data file that is part of the query.
Large tables may have many files and slower file systems, such as Amazon S3, will require more time than the timeout configured between the client and the Okera Policy Engine.
This inevitably leads to problems where queries time out during the planning phase.
Use the following configuration property to set the timeout value higher:
recordservice.planner.rpc.timeoutMs=300000 # 5 mins in milliseconds
See the FAQ article for more details.
Okera Enforcement Fleet (Worker) Timeouts¶
For batch jobs, processing may require a considerable amount of time, causing the connection between the client and the worker nodes to time out.
Use the following property to set the timeout value higher:
recordservice.worker.rpc.timeoutMs=1800000 # 30mins in milliseconds