Architecture Overview¶
The Metadata Services Overview and Cluster Component Overview documents introduce the major components of the Okera Data Access Platform (ODAP). This document takes the next step, explaining the Platform's architecture and showing the components in action for various client requests. It also shows more details on the possible deployment architectures, which can vary significantly, based on the user requirements.
Platform Architecture¶
On a more technical level, the Okera Platform is divided into services that are accessible for clients and a few other services that are only accessible internally by administrators or other services. This is intentionally the case to reduce complexity and concentrate access for clients to just a few locations. The following diagram shows all of the platform services in context.
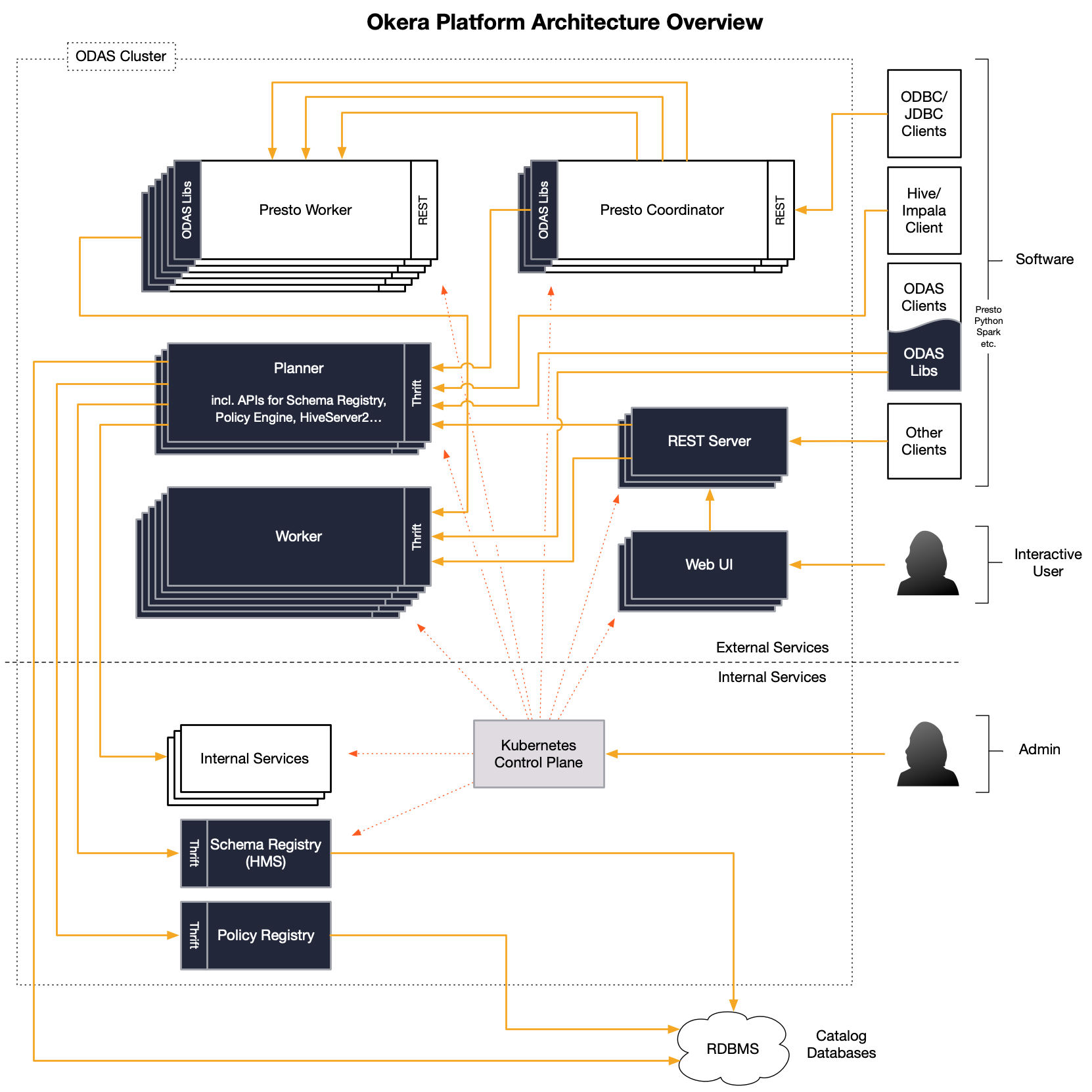
Client Access¶
The diagram starts in the top right corner with clients of varying kind communicating with the platform. There are three major access points:
Okera Web UI¶
Clients can use Okera web UI to interact with the underlying platform. The web UI provides access to the Metadata Services, such as the Schema Registry and the Policy Engine, and enables self-service dataset discovery. It also offers a workspace to issue SQL statements against the platform. Behind the scenes, this web application uses the REST API gateway service to interact with your platform's services, just the way your bespoke or customized applications can.
REST Gateway¶
Many clients have support for the ubiquitous REST protocol, avoiding most of the issues that arise when dealing with custom protocols. The REST gateway service gives access to the all necessary client API calls. This includes both the Schema Registry for creating, altering, or dropping various objects, as well as the Policy Engine for granting or revoking access related to all registered objects. See the Metadata Services API documentation for the list of supported REST calls.
Client Libraries¶
Finally, Okera provides a set of libraries for interfacing directly with the Metadata and Okera services, including the Okera Policy Engines (planners) and the Okera Enforcement Fleet (workers). This is the traditional way to integrate with the Metadata and Okera services. See Deployment Architecture for more on this topic.
Client Accessible Components¶
The Platform architecture diagram has a dashed line that separates the external services, which provide the client connectivity, from the internal support and management services. The following discusses the external and internal components separately, and how they work together to provide the services to all clients alike.
The external components in the architecture provide the major functionality of the platform, which is the data access and metadata management, as needed by clients such as interactive users to automated applications.
Note how the above referred to services, such as the REST API, Okera Policy Engine, and Metadata services. For fail-over purposes and continuous availability of these services, it is common in practice to have each service running multiple times. This is explained in greater detail in the High Availability documentation. In short, you can use the provided administrative functionality to instruct the platform to add redundant instances of the services (expressed as multiple, stacked boxes in the diagram) so that in case of a node failure the system will continue to operate.
The Okera Policy Engine service is also responsible for exposing the Metadata Services: the Schema Registry and Policy Engine. In effect, the clients use the REST API or client libraries as proxies (as shown in the diagram) to these two Metadata Services, provided by the Okera Policy Engine instances. The clients also communicate with the Okera Policy Engine as part of a query execution (see Communication below).
The Okera client libraries are used by many of the provided higher-level client integrations, including Hive, Presto, Spark, and others. This integration support is needed to hide Okera as much as possible behind common tools, with which users are already familiar. For example, enabling the Hive integration allows for existing Hive setups to switch from direct usage of underlying data sources to use Okera instead. There is no need to alter any metadata at all.
For Python, there are two different ways of communicating with an Okera cluster: which is using the REST API or the native PyOkera API.
Tip
Wherever possible, use PyOkera, as it performs markedly better than REST.
Communication¶
Once the cluster is operational, a client can communicate with the cluster services. Refer to the Authentication documentation for more details on how to secure the interactions between clients and an Okera cluster.
Read Request¶
The following sequence diagram shows how Presto, as an example interacts with Okera after Okera integration is enabled (see Hadoop ecosystem tools integration).
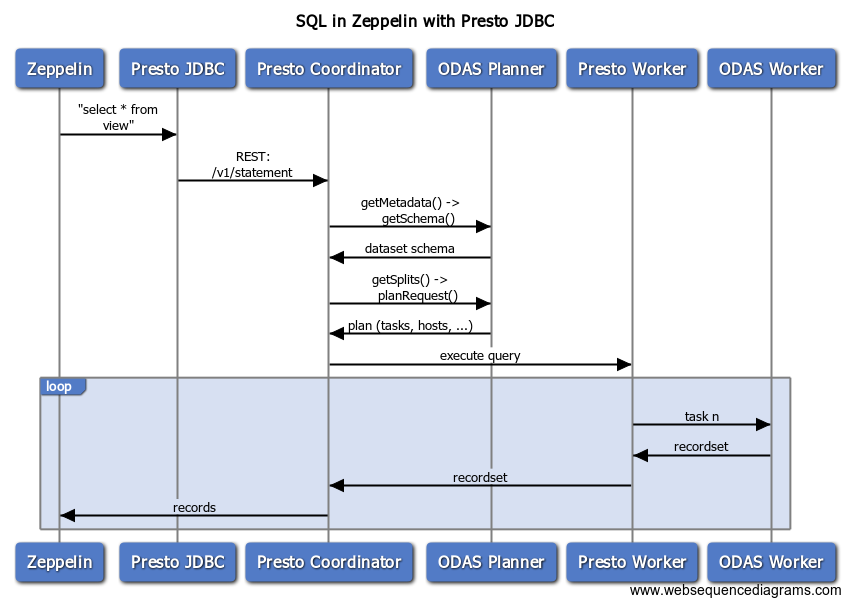
Depicted is a read request issued by Zeppelin (an interactive notebook service), showing the various calls made between the client and the services. Once a query is submitted in Zeppelin, it will use the Presto JDBC driver to plan and execute the request. The Okera Policy Engine is used to retrieve the dataset schema and instruct Presto how to distribute the query across its workers. Each worker is handed a list of tasks to perform, which is querying a subset of the resulting records.
Deployment Architecture¶
Depending on how clients interact with data, the Okera platform is flexible enough to adjust for the most ideal integration. This is important to strike the best balance between functionality, performance and, eventually, cost.
In practice, Okera is often provisioned on separate (virtual) machines, which incur operational costs. Okera is highly optimized for I/O: The core engine is written in C++ using the latest hardware acceleration functionality in a massively-parallel-processing (MPP) architecture. This means that a low number of Okera cluster nodes can serve compute engine clusters two magnitudes in size.
Having said that, there are use cases where the resource requirements are even lower. For instance, there are highly capable compute engines that already include many access control-related features. If a client operation only requires features that the engine provides, Okera can take a step back and - after rewriting the query - leave the operation execution to the engine for best performance.
Conversely, when the compute engine is ephemeral, that is, it is provisioned for a short amount of time but at a very large scale (think end-of-month analytics and report generation), then provisioning a matching Okera cluster might become more cumbersome. If those engines run on provisioned machines that allow co-location of auxiliary services (such as offered by Azure VMs) then Okera can be collocated on during the provisioning step and avoid any existing Okera cluster resizing beforehand or incurring extra cost for separate Okera cluster machines.
Common Deployment Architecture¶
The following diagram shows a common deployment architecture, where clients talk to multiple Okera clusters that serve different workloads (such as ad-hoc versus data pipeline clients) but share the same metadata.
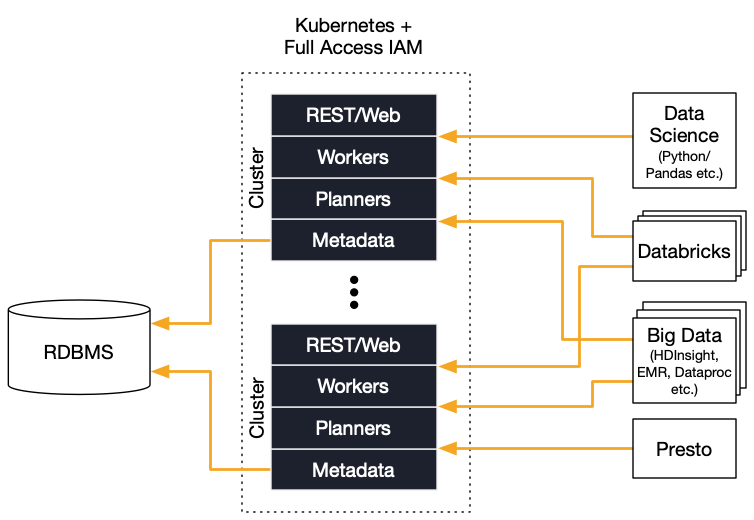
This setup has many flexible parts, for instance, you can run the Okera clusters - which are managed by Kubernetes - in a load-dependent manner. Okera clusters export operational metrics, which can be used with the infrastructure services to react to workloads. One of those uses AWS Auto Scale groups to scale clusters out and in automatically.
You can also set up clusters across multiple data centers (or regions) as well as across different infrastructure providers for any level of redundancy and failover safety. For high performance, Okera clusters are commonly deployed as close to the data as possible. The more lightweight metadata services can be shared, as shown in the Multi and Hybrid Cloud section of this document.
Separated Worker Architecture¶
The first change to the common setup is to separate the components that see the highest saturation. For the Okera clusters, this is the Okera Enforcement Fleet (worker) service. By separating the workers, the shared metadata services provided by the Okera Policy Engines can be operated more reliably and significantly reduce the impact of scaling clusters. For the latter, only the worker clusters need to be scaled out or in, while the metadata-related services stay the same.
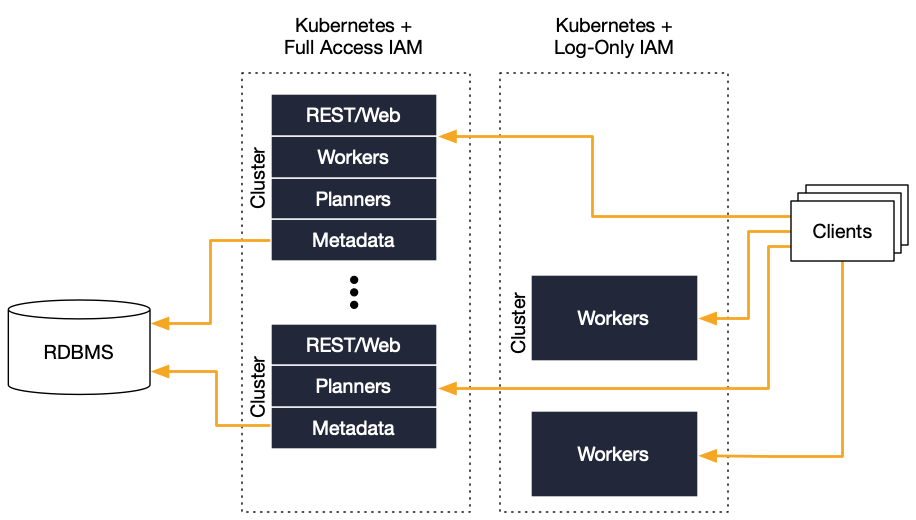
In addition, the worker clusters also can be operated with fewer access permissions related to the storage services. Instead, the shared metadata services provide temporary access to the required resources as necessary. For instance, in AWS this uses pre-signed URLs to access Amazon S3 files. This increases security overall as fewer services need infrastructure-level permissions.
Collocated Worker Architecture (nScale)¶
In addition to worker separation, you can co-locate the workers on the compute engine nodes. This capability is called nScale. It works for all services that allow auxiliary processes to be deployed during node provisioning.
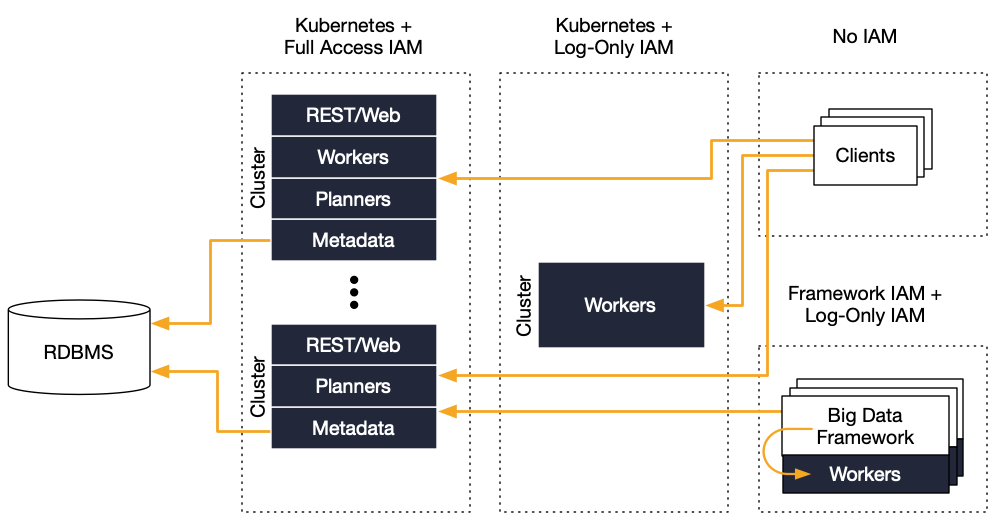
An advantage of nScale is that workers run in a non-elevated security context. In addition, nScale solves the cost concerns that can arise when operating Okera separately and being forced to match the scale out of the Okera cluster with the temporary computer cluster.
For additional information, including deployment information, see nScale Workers.
Multi and Hybrid Cloud¶
On top of running Okera clusters redundantly within a single cluster using service scale out, and the ability to scale using multiple Okera clusters, there is also the option to run Okera clusters across inherently heterogeneous environments. More specifically this comprises the following:
-
Multi-Cloud Support
This deployment architecture is used for enterprises that are conscious about depending on a single infrastructure provider. There are many reasons why diversifying infrastructure is a reasonable choice, not just for complying with laws and regulations.
In practice, this means that services are spread across multiple vendors, for example Amazon Web Services (AWS), Microsoft Azure, Google Cloud, and so on.
-
Hybrid Cloud Support
Another heterogeneous architecture is the combination of on-premises services with public cloud ones. This may be desirable for regulation compliance, but also for enterprises that are in the process of migrating to the cloud.
Okera clusters are platform-neutral, since they are provided as packaged container images that can be executed in common container environments. For on-premises, this may be RedHat OpenShift, which also uses Kubernetes under the hood to manage the services.
The following diagram shows how Okera clusters share metadata services across multiple, distinct infrastructure services.
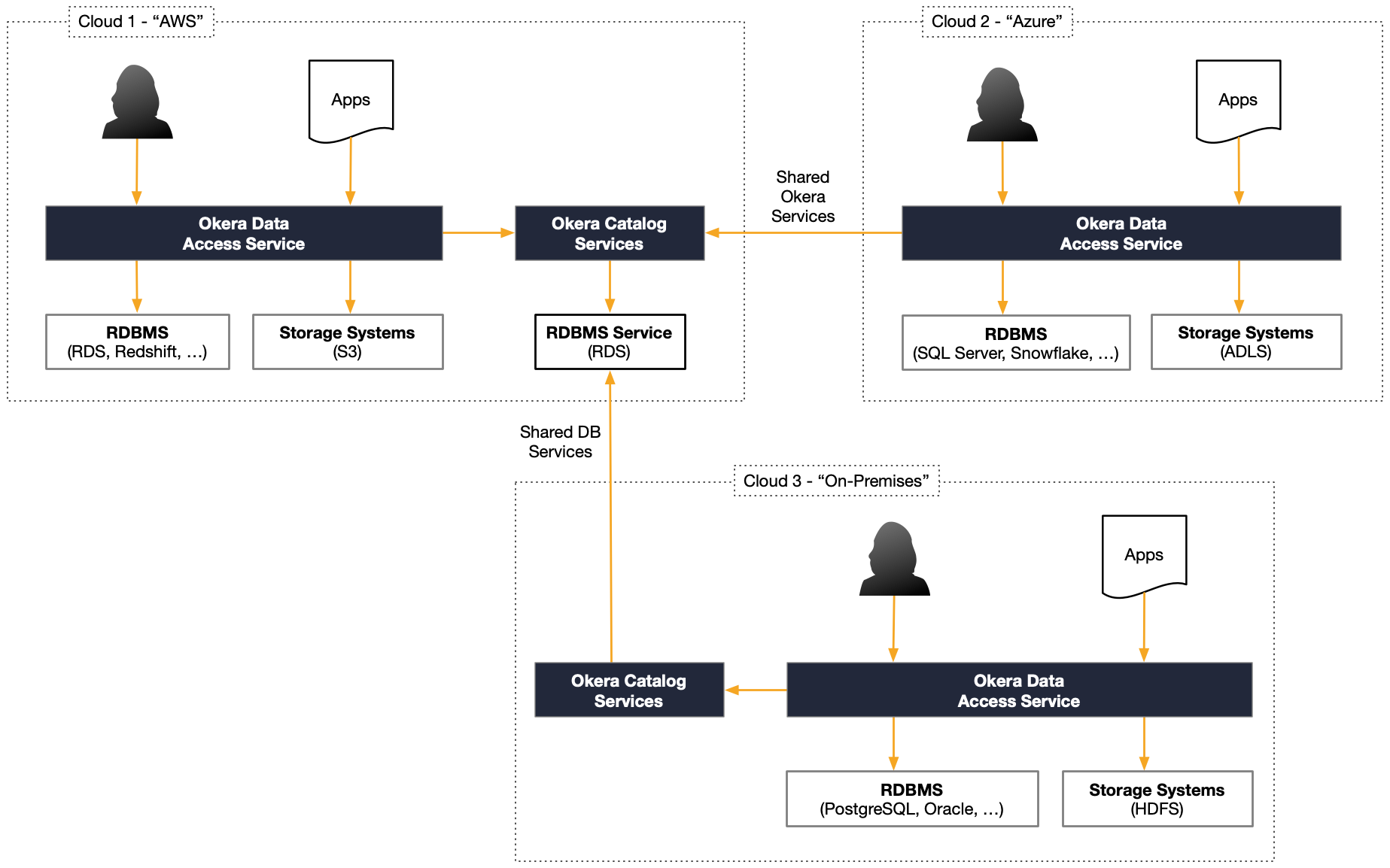
The deployment architectures shown above give great freedom on how you provision the Okera Platform. Please contact Okera if you have any questions.