Okera Version 2.5 Release Notes¶
This topic provides Release Notes for all 2.5 versions of Okera.
2.5.10 (1/10/2022)¶
This release contains an additional upgrade of log4j to resolve additional instances of the Log4Shell vulnerability.
2.5.9 (12/20/2021)¶
Bug Fixes and Improvements¶
- This release contains an additional upgrade of
log4jto resolve additional instances of theLog4Shellvulnerability.
Notable and Incompatible changes¶
- In past versions, Okera's operational logs did not use a partitioning scheme when uploading. This made it hard to locate the logs you needed and, in some environments, increased the time to list the log files. With this release, a new configuration option,
WATCHER_LOG_PARTITIONED_UPLOADShas been added to the configuration file to enable partitioned log uploads. Valid values aretrueandfalse. When enabled (true), operational log files will use theymd=YMD/h=H/component=Cpartitioning scheme for operational log file uploads. By default, this setting is disabled (false) so older clusters are not affected. However, in a future version of Okera, it will be enabled by default, so Okera recommends that users adopt this in new deployments.
2.5.8 (12/13/2021)¶
This release contains an upgrade of log4j to resolve the Log4Shell vulnerability.
2.5.7 (09/03/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue when using
Symlinktables where the manifest file containeds3a://...URIs instead ofs3://...URIs.
2.5.6 (07/19/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue when using transparent query pushdown for queries that utilize CTEs within inline views.
- Fixed an issue when using transparent query pushdown for queries that have mixed casing.
- Added support for specifying a default database in the connection session when using transparent query pushdown.
2.5.5 (07/08/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue when dropping partitions using the Hive/Spark client library.
- Fixed an issue that prevented some errors in the UI from being displayed on the Databases page.
Notable and Incompatible Changes¶
- This release contains an upgrade of the Alpine base image from 3.13 to 3.14, which upgrades the embedded Python from 3.8.x to 3.9.x (to address a Python CVE).
2.5.4 (07/05/2021)¶
Bug Fixes and Improvements¶
- Improved rendering performance in the Okera Workspace when rendering large tables.
Notable and Incompatible Changes¶
- This release contains an upgrade of the Alpine base image from 3.12 to 3.13 (and 2.5.5 will include an upgrade to Alpine 3.14), to address a Python CVE.
2.5.3 (06/18/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue when creating a crawler and using the "Dataset files are not in separate directories" option.
- Fixed an issue when dropping a partitioned table and using mixed casing for the database name.
- Fixed an issue when cascading tags on nested parts of complex columns to child views when multiple tags are present.
- Fixed an issue that can occur with MySQL 5.7 as the backing database.
2.5.2 (05/13/2021)¶
Bug Fixes and Improvements¶
- Fixed an issue with logging into Okera when another cookie is present on the domain (e.g., when using a SAML provider).
2.5.1 (05/05/2021)¶
Bug Fixes and Improvements¶
- Added the ability to control the partition split optimization threshold from Hive/Spark using the
recordservice.planner.partition-split-thresholdparameter. - Fixed an issue when rewriting
in_set(needle, haystack)when thehaystackwasNULL. - Improved the performance of
symlinktables (e.g., Delta and Hudi). - Fixed handling of SQL comments in Workspace.
- Added support for
BINARYdatatype for ORC files. - Added support for
IF NOT EXISTSandIF EXISTSforCREATE/DROP DATACONNECTION. - Fixed an issue when using MySQL 8 or higher as the backing database.
- Fixed an issue when updating view lineage.
- Fixed an issue when dropping some ABAC grants created in prior versions of Okera.
- Fixed an issue where error messages would not be cleared when re-running a data registration crawler.
- Improved performance of loading table metadata when many attributes are present.
- Fixed an issue when initiating a SAML login from the IdP.
- Improved handling of quoted values in
in_setrewrite. - Improved Okera cookie security by setting it to
httpOnly. - Fixed an issue when using multiple Snowflake warehouses in the same Snowflake account in the same Okera deployment.
Notable and Incompatible Changes¶
Login Cookie Changes¶
The Okera UI has changed its cookie to use httpOnly and is now managed by the server.
This approach improves security as no JavaScript code will be able to access information stored in the cookie.
Due to this, downgrading from 2.5.1 to 2.5.0, or to any prior version of Okera, in the same cluster will cause a UI login failure since the cookies are not compatible. To resolve this, you can clear all storage for the site, including cookies.
Snowflake Case-Insensitive Identifiers¶
By default, Okera will now set QUOTED_IDENTIFIERS_IGNORE_CASE to true when communicating with Snowflake, treating all identifiers as case-insensitive.
This behavior can be disabled by setting the OKERA_JDBC_CONNECTION_SNOWFLAKE_CASE_INSENSITIVE_COLUMNS configuration parameter to false.
2.5.0 (03/03/2021)¶
New Features¶
New Data Source Connections Experience¶
New UI experience to easily create connections to data sources. Read more on Connections.
Data registration now supports creating crawlers on any connection source (such as JDBC-backed data sources), not just object storage. Read more on Crawlers.
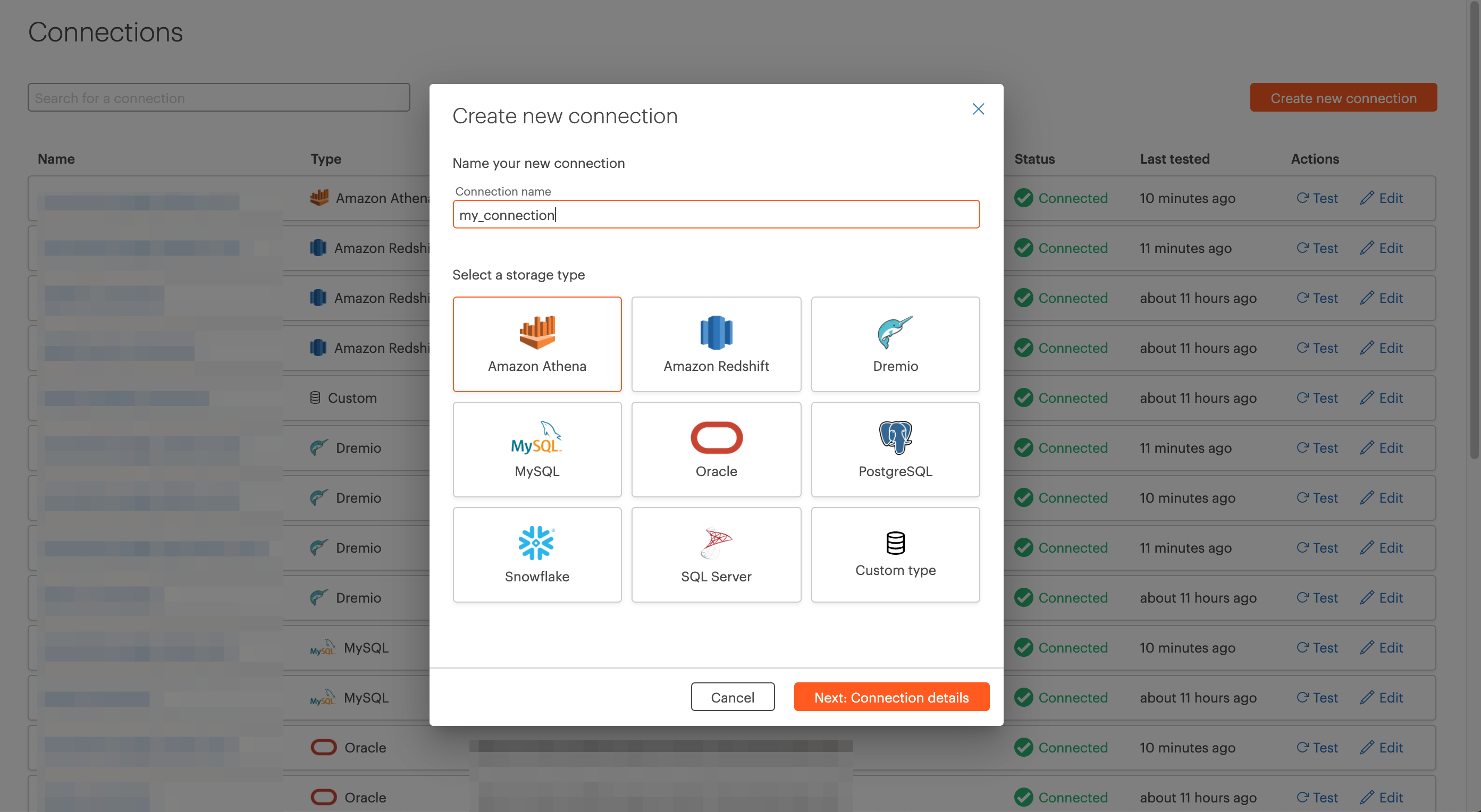
New Access Levels and Scopes for Data Management Delegation¶
Okera can now be used to grant granular permissions to delegate access to role, crawler and data connection creation and management.
As part of this, the ROLE, CRAWLER and DATACONNECTION object scopes have been added to the permissions model.
These new access levels and scopes are now available in the UI Policy Builder.
In addition, grants on URI are now also available in the Policy Builder.
These changes impact who can see the Roles page, the Registration page, and the Connections page in the UI. Click for more information on Access Delegation and for the full set of Access Levels available.
Dremio Integration (Beta)¶
Dremio is now a supported JDBC data source type, and you can read more about configuring it here.
User Attributes Improvements¶
A user's attribute values are now visible to that user from the homepage, including the user attribute source that provided them (e.g., ldap).
It is also now possible to configure a script (or multiple scripts) to source user attributes, which is useful if they need to be sourced from a bespoke location such as a custom REST API or storage.
To enable this, set the USER_ATTRIBUTES_SCRIPT configuration setting to a path where the script is available (or comma-separated paths), e.g., on Amazon S3 or a local file, and okctl will ensure those scripts are available inside the running pod.
Alternatively, if you are not using okctl, ensure that the value is set to a path (or comma-separated paths) that are available inside the container.
You can read more about user attributes here, and specifically about using custom scripts for sourcing them here.
ORC Format Support¶
Added support for the ORC file format, allowing to register and query data for files using this format.
Note: When you use the data registration experience to crawl for data in object storage, ORC data will not be automatically discovered. This will be added in a future release.
Easier Diagnostics Collection¶
Added the ability to use the EXECUTE DIAGNOSTICS DDL to automatically collect logs and other diagnostics to an Amazon S3 path.
The command will return immediately with the location the diagnostics are being written to, and they will be collected in the background.
By default, these diagnostics will be uploaded to a write-only Okera-owned bucket, okera-diagnostics, but this can be overridden:
- On a per invocation basis using
EXECUTE DIAGNOSTICS LOCATION 's3://...'. - By setting the
DIAGNOSTICS_COLLECTION_DEFAULT_LOCATIONconfiguration setting to a desired value (e.g.,s3://company-okera-diags/).
Note: Only administrators can run the
EXECUTE DIAGNOSTICScommand.
Improvements to okctl¶
- Added the ability to see the token claims using
okctl tokens describe <token>, where<token>is the name of the token file (in the.authfolder by default). - Added the ability to refresh a token using
okctl tokens refresh <token>, where<token>is the name of the token file (in the.authfolder by default). This will use the generated private key for refreshing, while preserving the groups in the token. - Added a
--durationflag for theinit,refreshandcreatesub-commands to control the duration that the token will be valid for. The default duration is one year. - Added the ability to disable specific validators (which may not be applicable to the environment) in the configuration YAML, by setting the validator to false:
validation: disk_space: true database: true ldap: true storage_read: true storage_write: true dns: true
Bug Fixes and Improvements¶
- Added the ability to specify a list of groups during role creation in the Okera UI.
- Added ability to add/remove multiple groups at the same time in the Okera UI.
- Added the ability to filter the permissions table by role name in the Okera UI.
- Fixed an issue where the Policy Builder summary would scroll away in lower resolutions in the Okera UI.
- Added ability to quarantine specific databases using the
QUARANTINED_DATABASESconfiguration key, which can be set to a comma-separated list of database names. - Added ability to specify a list of groups to grant to when creating roles, using
CREATE ROLE <role> WITH GROUPS group1 group2 .... - Added ability to specify more than one group when granting or revoking a role, using
GRANT ROLE <role> TO GROUPS group1 group2 ...andREVOKE ROLE ... FROM GROUPS group1 group2 .... - Improved the default timeout for communication between the built-in PrestoDB and the rest of the Okera services.
- Added ability to configure per-task and per-worker memory limit on nScale workers from various clients.
- Fixed an issue when using
CREATE EXTERNAL TABLE ... LIKE TEXTFILEwith a custom delimiter, where that delimiter would not be recognized for inferring the table schema. - Added the ability to specify a set of default delimiters to use when inferring schemas in
TEXTFILEby setting theOKERA_DEFAULT_FIELD_TERMINATORconfiguration setting to a list of characters. - Fixed an issue where the underlying connection to a JDBC-backed data source could leak in some cases when an exception happened.
- Added ability to control the default fetch size for JDBC-backed data sources by setting the
OKERA_JDBC_RECORDS_BATCH_MAX_CAPACITYconfiguration setting to the desired value. - Improved handling for data sources that do not support transparent query pushdown.
- Performance improvements for planning and execution of queries against JDBC-backed data sources.
- Fixed an issue when revoking a URI grant with a privilege level other than
ALL. - Added the ability to enable LDAP/SAML/OAuth UI authentication at the same time if more than one of authentication mode is necessary.
- Fixed an issue when fully unnesting a table that could cause column names that would exceed the metastore's limit of 128 characters. These columns are now auto-truncated to retain as much of the original name while fitting within the character limit. If a truncation is not possible, an error will be thrown.
- Fixed an issue when doing transparent query pushdown where it would incorrectly use the cluster-external load balancer (e.g., ELB) rather than the cluster-local service.
- Fixed an issue where a failed crawler would sometimes not report failure properly.
- Added the ability to specify the default
zstdcompression level by adding--zstd_default_compression_level=<level>toRS_ARGS. - Fixed an issue in which creating JDBC-backed tables could fail with a permission error.
- Fixed an issue in PyOkera where it would fail to properly parse the JWT if
pyjwtwas installed. - Fixed an issue in PyOkera where if both
dband afilterwere passed tolist_datasets, it would incorrectly omit thedbparameter. - Fixed an issue in the Okera UI where the "Use this dataset" sample text would not escape the database and table names.
- Fixed an issue when using
scan_as_pandaswhere it would incorrectly reset the row index for every batch. - Improved the behavior in PyOkera for refreshing the token when it is expired during a
scan_as_jsonorscan_as_pandasinvocation using theprestodialect. - Fixed an issue where the value of the
JWT_TOKEN_EXPIRATIONconfiguration setting would not always be used, instead using the default of 1 day expiration. - Improved memory accounting and dynamic batching when computing queries over large rows.
- Improved performance of JWT signature validation.
- Added the
in_set(<needle>, <comma-separated haystack>)built-in function. - Fixed an issue where the generated SQL could be missing enclosing parentheses when containing multiple predicates.
- Improved error handling when registering a set of tables using
ALTER DB ... LOAD DEFINITIONS(). By default (and changed from prior releases), an error will not be fatal and will continue registering tables. The number of tables added/skipped/failed can be seen by looking at theokera.jdbc.tables-XXXproperties on the database. To revert to the previous behavior of aborting on any error, set the configuration value ofJDBC_LOAD_DEFINITION_ABORT_ON_ERRORto true, either globally or per database (usingDBPROPERTIES). - Fixed an issue where the identifier quoting character for MySQL and PostgreSQL would not always be used when doing a query rewrite.
- Fixed an issue where timestamps that were too low to be represented correctly would cause incorrect values to be returned - the data is now clamped to the start of the Gregorian calendar.
- Improved handling of concurrent partition fetching for large partition counts.
- Fixed an issue where Okera could fail to drop a partitioned table when the
DROP TABLEDDL referenced the table in non-lowercase form. - Fixed an issue when creating a table without specifying a
ROW FORMATbut that does specify anINPUTFORMAT, causing the specifiedINPUTFORMATto be used by default for subsequent table creation when noROW FORMATis specified. - Fixed an issue where worker discovery could fail if one of the worker pods was stuck in
Pendingstate. - Added the ability to specify the result limit for
Prestomode queries as well in the Okera Workspace. - Fixed an issue when rendering complex types when running using the
Prestomode queries in the Okera Workspace. - Fixed a bug where Policy Builder failed to properly update policies when there was a conflict.
- Improved granularity of error reporting in Data Registration. There is now a distinction between an error during background crawling execution and an error regarding a specific table.
- Added the ability to search for crawlers by their
sourcein the Okera Data Registration UI. - Fixed a bug where crawler names that contained reserved characters were not being escaped.
- Removed the /__api/log endpoint, which was used by the Okera UI to log errors.
Notable and Incompatible Changes¶
Data Connections¶
- Connection names are now validated to only include allowed characters by default (
[a-zA-z_0-9]+). You can disable this behavior by setting theOKERA_ENABLE_CONNECTION_NAME_VALIDATIONsetting tofalse. - The
userandpasswordparameters when creating connections via DDL have been renamed touser_keyandpassword_key, to aid in understanding they do not store the credentials themselves but only the reference to them (e.g., in AWS Secrets Manager or a Kubernetes Secret). - In Okera 2.2.x and 2.3.x, when creating JDBC-backed data sources using a property file, Okera would implicitly create a data connection for it. This behavior is now disabled, as all new registration should happen using data connections. These automatically data connections cannot be used in the Data Registration flow and should ideally be replaced with explicitly created connections.
Permissions¶
Several permission-related changes were made in this release. These are generally part of the new permission delegation capabilities, but the notable changes include:
- To create a Crawler, a user now requires either the
CREATE_CRAWLER_AS_OWNERorALLprivilege on theCATALOGscope. - To use a data connection when creating a table or database, the user must have the
USEprivilege on that data connection. - To grant access to an object that a user has
WITH GRANT OPTIONon, that user will also needMANAGE_PERMISSIONSon the role they want to grant that permission to. To revert to the old behavior, set theENABLE_LEGACY_GRANTABLE_ROLESconfiguration setting totrue. -
Starting in 2.5.0, access to the Okera Workspace will be granted to all users (it is granted by default to
okera_public_role). If you wish to limit access to Workspace to specific users:- Revoke access to Workspace by removing it
okera_public_role. You can do this from the Roles UI or by running the DDL:
REVOKE SELECT ON TABLE okera_system.ui_workspace from ROLE okera_public_role;- Edit your cluster configuration to the value for
GRANT_WORKSPACE_TO_PUBLIC_ROLEtofalse.
You can then grant the
okera_workspace_roleto any specific groups or users that you want to have access to the workspace feature. - Revoke access to Workspace by removing it
-
Starting in 2.5.0, access to the following pages is controlled by whether the user has access to the relevant object, as opposed to explicitly granting access to that page. Read more about this here:
Roles: access to theRolespage is now available if the user has permission to manage anyROLEobject.Tags: access to theTagspage is now available if the user has permission to manage anyATTRIBUTE NAMESPACEobject.
Other Updates¶
- Database, dataset, and catalog filters have been removed from the Roles page. Permissions now appear on their respective objects on the Data page.
- If a user has two grants to the data, one which is on an entire scope (e.g., table/database/catalog) with no
WHEREclause, and one which has aWHEREclause, theWHEREclause will no longer be added as the other grant provides full access.
SQL Keywords¶
The following terms are now keywords, starting in 2.5.0:
CREATE_CRAWLER_AS_OWNERCREATE_DATACONNECTION_AS_OWNERCREATE_ROLE_AS_OWNERDENYMANAGE_GRANTSMANAGE_GROUPSMANAGE_PERMISSIONSPOLICYPROPERTIES