Okera Version 2.10 Release Notes¶
This topic provides Release Notes for all 2.10 versions of Okera.
2.10.7 (10/23/2022)¶
Bug Fixes and Improvements¶
- Updated the Okera Spark3 connector to address an incompatibility resulting from a Databricks library change in Okera-supported Databricks runtime versions 9.1 LTS and later.
2.10.6 (10/19/2022)¶
Updated Input to LDAP Filtering¶
In this release, we have updated Okera's input for LDAP filtering. Two new configuration parameters have been defined to allow you to specify separate base DNs (distinguished names) for users and groups for LDAP server searches during its authentication processing.
- Use
GROUP_RESOLVER_LDAP_USER_BASE_DNto specify the base DN for users. - Use
GROUP_RESOLVER_LDAP_GROUP_BASE_DNto specify the base DN for groups.
See Okera Configuration Parameter Reference for a complete list of the configuration parameters available to you for Okera configurations.
Security Vulnerabilities (CVEs/CWEs) Addressed¶
- CVE-2021-4209 Null Pointer Dereference
- CVE-2022-2509 Double Free
- CVE-2022-2526 Use After Free
- CVE-2022-37434 Out-of-Bounds Write
- CVE-2022-40664 Improper Authentication
Okera uses Snyk and GitHub Advanced Security for security vulnerability scanning.
Bug Fixes and Improvements¶
- Fixed a bug so that the correct STS credentials are used when refreshing presigned URLs.
2.10.5 (9/13/2022)¶
Security Vulnerabilities Addressed¶
- CVE-2020-17523 Authentication Bypass
- CVE-2020-25649 XML External Entity (XXE) Injection
- CVE-2020-28483 HTTP Response Splitting
- CVE-2020-36518 Out-of-bounds Write
- CVE-2022-21434 Oracle Java SE Vulnerability
- CVE-2022-23437 XML Injection
- CVE-2022-25647 Deserialization of Untrusted Data
- CVE-2022-29155 Ubuntu USN-5424-1 OpenLDAP Vulnerability
- CVE-2022-29458 Out-of-Bounds Read
- CVE-2022-31197 SQL Injection
- CVE-2022-34169 Incorrect Conversion between Numeric Types
- CVE-2022-37434 Out-of-bounds Write
Okera uses Snyk and GitHub Advanced Security for security vulnerability scanning.
Bug Fixes and Improvements¶
- Upgraded Okera's version of Jackson to 2.13.3.
-
Okera's base Ubuntu image has been upgraded to bionic-20220801.
-
Upgraded Okera's base Alpine version to 3.15.6.
-
Upgraded Okera's version of Apache Shiro to 1.9.1.
-
Upgraded Okera's version of OpenJDK to 8.345.01-r0.
-
The policy synchronization enforcement mechanism used for Snowflake connections is now no longer enabled by default. You must enable it manually using the
POLICY_SYNC_SCHEDULER_ENABLEDconfiguration parameter or theokera.policy_sync.enabledadvanced parameter in your Snowflake connection.
-
Updated gin-gonic to v1.7. 3.
-
Fixed the CSP headers for the REST API documentation.
-
Upgraded Scala in recordservice-spark-2.0.jar to version 2.11.12.
2.10.4 (7/13/2022)¶
Dropping Attributes From Nested Fields¶
This release introduces the ability to drop attributes from nested fields. See Nested Field Tags.
Security Vulnerabilities (CVEs) Addressed¶
- CVE-2022-2097 Inadequate Encryption Strength
- CVE-2022-22576 Improper Authentication
- CVE-2022-22747 NSS Issue
- CVE-2022-24765 Uncontrolled Search Path Element
- CVE-2022-27775 Curl
- CVE-2022-27781 Loop with Unreachable Exit Condition ('Infinite Loop')
- CVE-2022-27782 Improper Certificate Validation
- CVE-2022-29187 Uncontrolled Search Path Element
- CVE-2022-32205 Allocation of Resources Without Limits or Throttling
- CVE-2022-32206 Allocation of Resources Without Limits or Throttling
- CVE-2022-32207 Incorrect Default Permissions
- CVE-2022-32208 Out-of-Bounds Write
- CVE-2022-34480 NSS Issue
- CVE-2022-34903 Arbitrary Code Injection
Okera uses Snyk and GitHub Advanced Security for security vulnerability scanning.
Bug Fixes and Improvements¶
- Fixed an issue in which database passwords with special characters were not properly encoded when establishing a connection.
-
Corrected a problem with string data when using Avro complex data types for certain unnesting queries.
-
Users who do not have permissions to create Okera databases now receive an authorization error if they attempt to create a database that already exists.
-
Fixed an issue in which the Presto configuration was written with mismatched closing tags.
2.10.3 (6/29/2022)¶
AWS Athena Upgrade and Performance Improvements¶
This release upgrades Okera to use the AWS Athena 2.0.30 JDBC driver. With this upgrade, the Athena JDBC JAR file is no longer provided by Okera in the Maven repository, so you must download it from https://docs.aws.amazon.com/athena/latest/ug/connect-with-jdbc.html. Okera does not require a JDBC driver with the AWS SDK, so download the one without the AWS SDK. In addition, Okera connections to Athena also now require specification of the path to the JDBC JAR file and its class name, specified in the driver.jar.path and driver.class.name properties in the connection. If you are creating an Athena connection in the Okera UI, these properties can be specified in the Driver file path and Driver class name fields. See Athena Data Source Connections.
Starting with Athena 2.0.5, the Athena JDBC connector uses the result set streaming API to improve its performance when fetching query results. To use this new Athena feature:
-
Include and allow the
athena:GetQueryResultsStreamaction in your IAM policy statement. For details on managing Athena IAM policies, see https://docs.aws.amazon.com/athena/latest/ug/security-iam-athena.html. -
If you are connecting to Athena through a proxy server, make sure that the proxy server does not block port 444. The result set streaming API uses port 444 on the Athena server for outbound communications.
Active/Active In-Parallel Policy Loading¶
This release introduces the ability to load Okera policies in parallel when active/active environments start up. This speeds up service start time, particularly for slower RDBMS environments or environments in which many roles must be loaded. Okera uses two thread pools to perform active/active in-parallel policy loading, one for the initial load and one that occurs in the background. The default number of roles loaded in parallel for an initial load is 12; the default number of roles loaded in the background is 2. To control these settings, two new configuration parameters have been introduced:
SENTRY_INITIAL_LOAD_THREADScan be used to override the initial in-parallel load default of12roles. Specify the number of roles that should be loaded in parallel when an active/active environment is initially started.SENTRY_BACKGROUND_LOAD_THREADScan be used to override the background in-parallel load default of2roles. Specify the number of roles that should be loaded in parallel in the background of an active/active environment.
For more information about active/active environments, see Active/Active Deployment in Aurora RDS. For more information about Okera configuration parameters, see Configuration and Okera Configuration Parameter Reference.
Security Vulnerabilities (CVEs) Addressed¶
- CVE-2022-29361 HTTP Request Smuggling
Okera uses Snyk and GitHub Advanced Security for security vulnerability scanning.
2.10.2 (6/17/2022)¶
Configuring Parquet File Resolution Types¶
Table property parquet.resolve-by.type can now be used to configure how a Parquet data file is resolved. Valid values are ordinal (positional resolution) and name (name resolution). In past releases, resolution was configured globally and by default, resolved by name.
For example:
ALTER TABLE nation SET TBLPROPERTIES('parquet.resolve-by.type'='name')
ALTER TABLE nation SET TBLPROPERTIES('parquet.resolve-by.type'='ordinal')
Bug Fixes and Improvements¶
- Snowflake pushdown processing now supports queries using column tags (tag-based row filtering).
2.10.1 (6/7/2022)¶
Bug Fixes and Improvements¶
-
Upgraded to the latest version (2.1.0.7) of the Redshift JDBC driver.
-
A
Content-Security-Policyheader is now applied to the REST server resources used by the Okera UI.
-
Improved the performance of Okera metadata queries when calling Databricks with JDBC.
-
Improved Okera performance when evaluating ABAC policies.
-
Improved performance when authorizing datasets from Databricks.
-
Improved the performance of AuthorizeQuery RPC calls.
-
Improved performance when using policies with transform clauses.
-
Improved performance when authorizing table access from Databricks.
-
Improved Okera performance when loading table metadata.
2.10.0 (5/16/2022)¶
New SaaS Offering¶
With this release, Okera introduces its software-as-a-service (SaaS) offering.
In this first release of Okera's SaaS offering, only Snowflake data sources are supported. Support is planned for other data sources in future releases. In addition, you can now see which data sources are supported in your Okera environment in the Allowed Datasources field on the System Information page.
User management capabilities are provided in Okera's SaaS deployment for account admins. All other SaaS tenant users can access their user profiles and change their passwords. For more information, see Okera SaaS User Management.
Tag-Based Row Filtering¶
This release adds the ability to use row filtering based on a column tag. You can still filter based on column name, but because column names can vary between datasets, using a column tag for filters provides more flexibility and is easier to set up.
For example, suppose one dataset in a database includes a column named country (populated with country names) and another dataset in the database includes a column named nation (also populated with country names). If you create permissions based on the column name, you will have to create two permissions, one for each unique column name. But if you tag the country and nation columns with a tag named company.location (for example) and create permissions based on the tag name, only a single permission is necessary at the database level to cover both datasets.
Column tags can be filtered for values or for user attributes. For example, you could create a row filter for the company.location column tag that provides access only where the value equals France or where the value matches the user attribute country.
To accommodate this functionality, the following changes have been made to the permission dialogs:
- A new Column with tag option is added to row filtering access conditions.
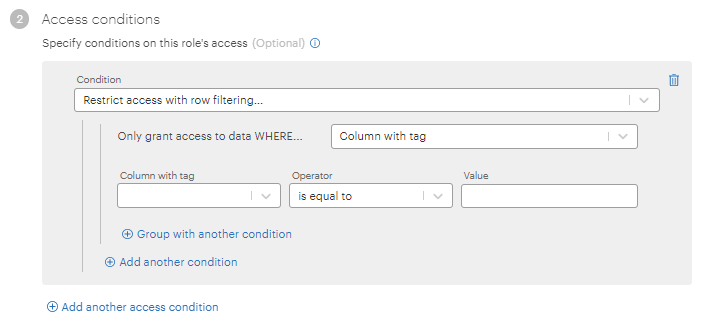
- The operators listed in the Operator dropdown are now separated by distinct type: value or user attribute.
For more information, see Row Filtering by Column Name or Column Tag.
Snowflake Policy Synchronization Configuration Script¶
A new Snowflake configuration script is provided to help you configure your Snowflake environment for Okera policy synchronization enforcement. See Use the Supplied Configuration Script.
Self-Service Trial Enhanced With Snowflake Policy Synchronization¶
Snowflake policy synchronization has been added as a tool and lesson in the self-service trial. See Use Snowflake Policy Synchronization.
-
Self-service trial tenants are preconfigured with an Okera Snowflake connection and two data crawlers. These enable access to a user-specific Snowflake database and schemas. A single script is provided in Snowflake containing SQL queries to run during the trial.
-
The usernames provided as part of the trial environment now include a tenant name to ensure they are unique, especially as users are added to the trial from different companies. For example, tenant
mycompanywill log in to Okera with usernamesadmin_mycompanyandsally_mycompany. These updated usernames are now used throughout the trial environment. The old usersadmin,danny,sally, andsamare deprecated. -
User credentials are included in the self-service trial welcome email, as before, but the email now lists which users have Snowflake accounts and provides a link to the Snowflake console. While all provided users can log in to Okera, Superset and JupyterHub, only the following have Snowflake access:
admin_<tenant>,sally_<tenant>,sam_<tenant>, anddanny_<tenant>.
Active/Active Deployment ¶
You can now run multiple Okera clusters in separate regions that share data using an Amazon Aurora relational database service (RDS) with write-forwarding enabled.
The cluster in each region communicates with its local read-only database. Aurora RDS synchronizes updates between the primary instance and its replicas in each region. This environment allows multiple active Okera environments to share data and is called an active/active environment. See Active/Active Deployment in Aurora RDS.
Presto Resource Group Support¶
This release introduces the ability to enable Presto resource groups that can be used for quality of service and admission control management. These resource groups can be used to constrain the resources used by a single user or query. For more information about Presto resource groups, see Resource Groups.
To enable these Presto resource groups, add the following configuration parameters to your Okera configuration file and restart Okera.
-
PRESTO_SHOULD_USE_RESOURCE_GROUPS: Set this parameter totrueto enable the file-based configuration manager for Presto. Valid values aretrueandfalse. The default isfalse. -
PRESTO_RESOURCE_GROUP_FILE_LOCATION: This parameter identifies the location of a JSON file that contains the Presto resource group definition. Information about the contents of this file can be found in Resource Groups.
Presto Query Logging Support¶
This release introduces support that logs additional Presto query information. Presto provides high-level information about queries that does not ordinarily get logged in Okera. When you enable this new support, additional information is logged in Okera logs, allowing you to better understand which queries are running, which ones succeed and fail, and how failures occur.
To enable Presto query logging, add the new PRESTO_ENABLE_QUERY_LOGGING configuration parameter to the Okera configuration file, set its value to true, and restart Okera. Valid values for this new configuration parameter are true and false. The default is false.
SailPoint Integration¶
This release introduces support for integrating Okera with SailPoint. This integration allows Okera to use SailPoint cross-domain identity management (SCIM) APIs to pull and add enhanced user properties for Okera users and display them on the Users page in the Okera UI. The properties can then be used to configure access permissions in Okera. The properties pulled from SailPoint into Okera can be configured. For more information, see Obtaining SailPoint User Attributes in Okera.
New Performance-Tuning nScale Setting for Hive and Spark Requests¶
A new, optional, performance-tuning nScale setting called recordservice.task.plan.defer-signing-urls has been added in this release. It indicates whether presigning URIs in all tasks should be deferred for nScale requests initiated from Spark and Hive. Valid values are true (defer presigning URIs in plan requests) and false (continue presigning all URIs in plan requests). The default is false.
This update also:
-
Adds two PyOkera arguments:
cluster_idanddefer_task_url_signing. For more information, read about the arguments for theplan()PyOkera metadata API. -
Changes the default number of tasks for which deferred signing occurs from 256 to 64. This is specified by the RS_ARGS option
defer_signed_urls_initial_num_tasks. See RS_ARGS Options. -
Adds a new server-side RS_ARGS option:
defer_signed_urls_initial_percent_tasks. This option specifies the percentage of nScale tasks for which deferred signing should be performed. The default is 25%. Okera defers signing for 64 tasks (the newdefer_signed_urls_initial_num_tasksdefault) or for this percentage of all nScale tasks, whichever is lower. See RS_ARGS Options. -
Finally, all requests to refresh tasks containing presigned URIs are logged in the audit log.
See Deferred URI Signing Settings for nScale.
OkeraEnsemble Assume Secondary Role Support¶
Assume secondary role support (also referred to as bucket role mapping) is now supported in OkeraEnsemble Amazon S3 environments. This support introduces two new configuration parameters: OKERA_ASSUME_ROLE_DURATION_SECONDS and GO_ACCESS_PROXY_CACHE_LOG_PERIOD. For more information about bucket role mapping and these new parameters, see Amazon S3 Assume Secondary Role Support. For information about OkeraEnsemble, see OkeraEnsemble Deployment on Amazon S3.
New Databricks Environment Variable¶
This release introduces a new Databricks environment variable, OKERA_BUILTINS_DB, for Okera. This parameter specifies the location of Okera's supplied user-defined functions (UDFs). This parameter should only be set if the EXTERNAL_OKERA_SECURE_POLICY_DB configuration parameter as specified in Okera's configuration file. The values for two parameters must match. Both settings default to okera_udfs. See Databricks Integration Steps.
Notable Changes¶
- Support is deprecated for the following versions of Amazon Elastic MapReduce (EMR): 5.20, 5.21, 5.22, and 5.23. The earliest version of Amazon EMR currently supported by Okera is version 5.24.
Bug Fixes¶
The following bugs were fixed in this release:
- The Google Cloud CLI (
gcloud) is now shipped in Okera containers.
- The user option menu, in the bottom left corner of the UI navigation menu, has been redesigned. See New SaaS Offering.
- Crawler errors are now shown on the Crawler details page.
- Fixed a bug that occurred when a complicated policy with many conditions would not save. The character limit for Okera Snowflake policies has increased from 1000 characters to 5000 characters in this release.
- Fixed an issue where Snowflake policy synchronization failed with a connectivity error if the Snowflake connection host name included more than two periods (".").
- Postgres has been removed from Okera images. Okera builds included Postgres in previous versions.
- Optimized metadata loading when analyzing ALTER TABLE DROP PARTITION statements.
- Fixed two crawler bugs. The crawler information page can now be accessed, even if the crawler fails. In addition, when a crawler fails, the crawler information page now shows the correct status.
- Okera now supports UUID data types for JDBC data sources. They are mapped to the STRING data type in Okera. See JDBC Data Types Mapping.
- Fixed a problem in which a user encounters an error accessing a URI when they are granted catalog/server-scope permissions which have associated attributes.
-
Fixed a bug in which the Select statement for an internal view failed with a null pointer exception when
columns_with_attribute()user-defined functions (UDFs) were used. -
By default, Okera connections now use
autocommit=truewhen connecting to the RDBMS for system state actions. -
Fixed a bug in which a connection containing a previously synchronized Snowflake view caused subsequent synchronizations to fail because we were not generating the proper DDLs to adjust the policies on views.
- Upgraded the base Alpine image used by Okera to 3.14.6.
- Reverted the formatted result change made for SHOW CREATE TABLE and SHOW CREATE VIEW statements in version 2.9.0 because it caused errors in some external tests. Plans are in place to reinstate this update in another way.
- Fixed a case where request IDs were not logged during a policy sync.
- Fixed a bug where Snowflake users with quotes in their names caused policy sync failures.
- The issue where too many open files in the REST server log led to error responses for OkeraEnsemble clients is fixed.
-
Fixed a bug that did not show the data transform condition in the permission conflict table.
-
Fixed a bug that did not allow you to change a permission if permission conflicts exist.
- Fixed an issue where connections to Azure Key Vault failed.
-
Fixed a bug in which the date offset in Snowflake did not account for daylight savings time.
-
Fixed an issue in which the Snowflake audit log sync ran on both Okera Policy Engine (planner) and Okera Enforcement Fleet worker instances. It should only happen on the Policy Engine instance.
- Fixed an issue where nScale workers would not start.
- Added support for
decimaltypes in core tokenize user-defined functions (UDFs).
- OAuth with OpenID Connect now allows a way to configure which part of the
id_tokenis used to identify the user. In previous releases,subwas always used. Now, theOAUTH_OIDC_USER_CLAIM_KEYconfiguration parameter can be used to identify theid_tokenkey to use as the user identifier. For example, to useemailinstead ofsub, specifyOAUTH_OIDC_USER_CLAIM_KEY: emailin the Okera configuration file. If not specified, the default issub.
- ALTER TABLE statements now support changes to multiple partition locations in a single DDL.
-
Google OAuth is now supported. To enable it, include the following Okera configuration setting, in addition to the required OAuth configuration settings:
OAUTH_PROVIDER: google. Okera treats the OAuth provider as a generic OAuth 2.0 provider, which will work for many OAuth 2.0 providers without additional configuration. However, if you do not set this configuration setting, it will not work for Google or G Suite (Google Workspace). The only valid value for this setting isgoogle. See Authenticate Using Open Authorization (OAuth). -
Okera's Databricks cluster bootstrap script now supports downloading client libraries from any Apache Maven artifactory.
- Performance is now improved when evaluating grants of the form
HAVING ATTRIBUTE not in <attribute name>andHAVING ATTRIBUTE not <attribute name>.
- Added support for all Okera AWS CLI versions through the latest version, 1.22.71. Support before this change may have been limited to the default installation of Amazon Linux 2 (AWS CLI version 1.18.147).