Overview¶
Okera is data access management for enterprise-scale operations with complex technical and organizational infrastructure. It enables data stewards, analysts or scientists, and application developers alike to engage with any company data appropriate to their role, using their preferred querying and visualization tools. Okera accomplishes this while obeying security- and regulatory-based access limitations.
Whatever your storage or streaming environments, Okera brings your data together with a common retrieval platform, which includes cataloging services such as a schema registry, while expanding and simplifying overall access without exposing data improperly. The platform provides largely self-service access to data consumers through consistent schemas, intelligent governance, and familiar interfaces.
Why Okera¶
Let's agree: you already have too many data storage and management systems, each with their own administration and query overhead. Some of them are governed by schemas and sophisticated access controls, but others likely are not. None of the data sources or structures plays nice with any global system for filtering or masking data.
The only way yet another data platform deserves a place in your overcrowded stack is by creating coherence out of disparate underlying systems, from RDBMS to NoSQL systems alike, all while unifying data access management without sacrificing fine-grained control.
Okera's unified data access platform lives between your disjointed data storage systems and the tools used to access and analyze data. Deployable on any kind of infrastructure, the Okera platform enables a consistent user experience while accessing data across environments. Whether you're running, for example, Hadoop in your own data center or Elastic MapReduce in Amazon Web Services, Okera ties your sources together.
Okera reduces the incentive to store data in ways that make less sense just to provide better access. Okera also enables business users to engage with data using their preferred tools where often they have been relegated to systems that conformed to the underlying data needs.
The platform also enables data-engineering teams to automate complex management tasks required to support this variety of workloads and combination of systems. The alternative is multiple and complex engineering efforts with long development cycles, which thwarts the goal of efficient, fast, secure, and governable self-service access.
The Platform¶
Okera's core components provide unified metadata and data access interfaces in the form of readily scalable, fault-tolerant, distributed services.
Okera Metadata Services¶
The Okera Metadata Services are a set of distributed services that coordinate, for example, storing dataset definitions, access policies, and other metadata. They are intended to be shared across multiple teams and across Okera clusters, consolidating effort and standardizing the way data infrastructure is understood across the enterprise.
Using Okera Metadata Services, data owners or stewards publish access policies and datasets. They also audit access to data they want to share with specific roles or teams, such as for analytics or building new applications and data pipelines. Meanwhile, data analysts or scientists use the Metadata Services to discover and understand datasets. The Metadata Services enable these end users to request access to data as needed.
For more about Okera Metadata Services, see the Okera Metadata Services Overview.
Okera Cluster Component Services¶
Okera cluster component services enable analytics tools and other custom or third-party applications to interact with data governed by the Okera platform. Okera provisions data to third-party tools with schema, fine-grained security, and data transformations applied. The platform facilitates abstraction in the familiar forms of tables or files in formats the user may request. Different retrieval, streaming, and analytics tools like Spark, Python, SQL engines, Notebooks, and business intelligence tools like Tableau, Excel, and so forth work seamlessly and transparently to the end-user.
Multiple instances of Okera can run in a single environment. Some may be ephemeral, others persistent. Some may be running as independent services whereas others may be collocated with the analytics framework. The deployment model depends on the performance and isolation requirements.
For more about Okera cluster components, see the Cluster Component Overview.
Okera Web UI¶
The Okera web UI is a web-based user interface that can be used to discover datasets provided by the Metadata Services, browse dataset content, inspect user and group permissions, as well as issue SQL commands. See the Okera UI Basics documentation for more details.
Where Okera Fits¶
Now that we know a bit about what Okera does, let's look at where it sits. Okera runs on dedicated clusters, either on-premises or in your preferred cloud environment, such as AWS. A typical Okera setup involves a single set of shared Catalog services and one or more instances of Okera, as needed.
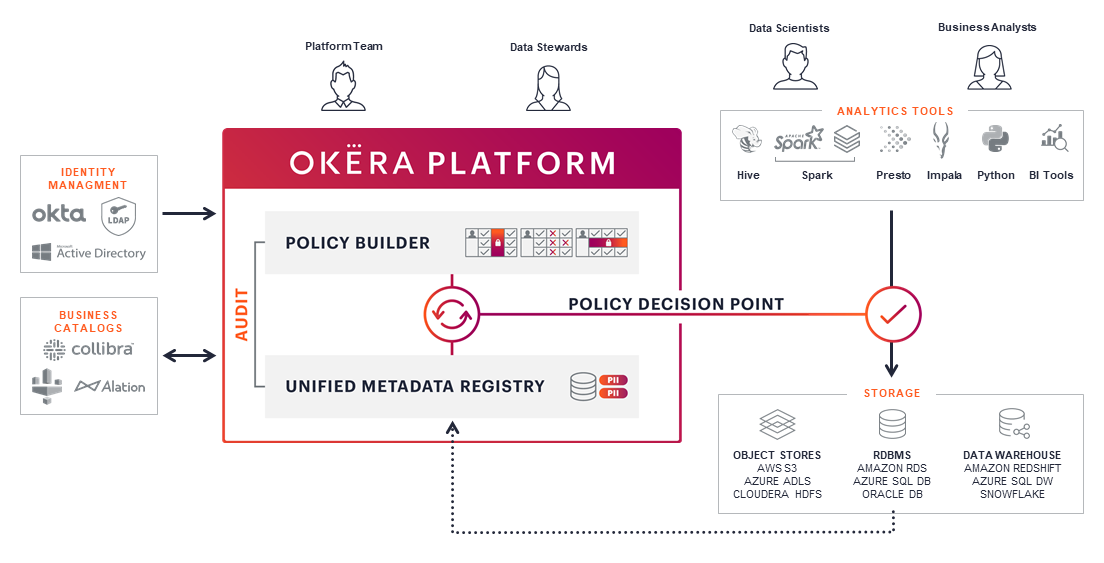
Okera User Roles¶
Users interact with Okera platform in one or both of two broad roles: producers and consumers. Consumers and producers alike need to know how to find, contextualize, and retrieve data over the Okera platform. Consumers may interact with Okera-managed data exclusively through the Okera platform. Producers, on the other hand, are typically responsible for writing or managing data directly, which means they use the Catalog service to manage metadata.
Data Consumers¶
Business analysts and data scientists access data over Okera as consumers. They use Okera Catalog to discover and contextualize datasets, but not necessarily to manage them.
Data Producers¶
Data engineers and data stewards, and possibly analysts or scientists with responsibility for managing data will use Okera Catalog to register new datasets as well as apply metadata and schemas. Producers also audit other users' access to datasets.